

Los datos son la base de nuestros sistemas. La materia prima de la que se alimentan nuestras aplicaciones y análisis. Ya sea por renovación de un sistema, o por un cambio de arquitectura que cambia el soporte de almacenamiento, o como respuesta a la necesidad de asimilar datos de otras fuentes, el movimiento de datos es una de los retos mas complejos y críticos a los que nos podemos enfrentar.
En primer lugar, no podemos perder datos. El traspaso, sea periódico, o no (como sería el caso de una migración, que se hace una sola vez… si nada falla) debe garantizar este hecho. También, por regla general, el movimiento requerirá de transformaciones y conversiones de la información, por ejemplo, para adaptarla a la arquitectura del sistema destino. En casos como la migración de datos, son requeridas detenciones en el servicio, deteniendo el sistema de origen hasta que el sistema de destino está plenamente operativo.
En otros, como la ingesta de información de fuentes externas, el foco se centra en la necesidad de transformar los datos para que encajen en nuestros sistema, sin olvidar problemas como el rendimiento o el no afectar al servicio de la fuente origen ni el del destino.
Para aquellos casos en los que el traspaso de datos es periódico, o al menos va a ser reproducible, podemos contar con una poderosa herramienta, que nos puede ayudar a realizar esta tarea.
Apache NiFi es un motor de ejecución de flujos de enrutamiento y transformación de datos. Dicho de forma simple, carga datos de una fuente, los pasa por un flujo de procesos para su tratamiento, y los vuelca en otra fuente.
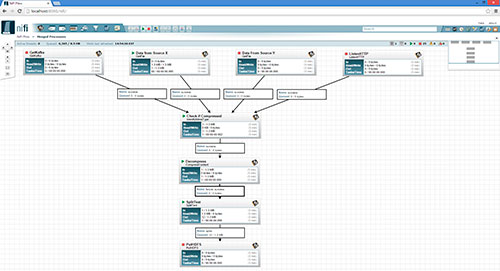
En este ejemplo podemos ver como se ha definido un flujo en el que datos de varias fuentes se unifican, antes de pasar por una serie de procesadores, para terminar almacenados en un soporte común. Este flujo puede ramificarse tanto como sea necesario.
Interfaz de usuario
La aplicación web de Apache NiFi es uno de sus puntos fuertes. No sólo permite diseñar y configurar de forma visual el flujo por el que viajarán los datos, sino que, desde esa misma vista, se pueden tanto operar sobre el proceso (arranque y parada) como monitorizar el estado, viendo los posibles errores que se hayan producido.
Este flujo puede modificarse durante su ejecución, simplemente, deteniendo el proceso en un punto, y realizando los cambios. Los datos se encolan en el paso anterior, hasta que se reanude la ejecución.
Procesadores
Cada una de las cajas que forman parte del flujo, los procesadores, aportan una funcionalidad concreta al flujo. NiFi viene pre-cargado con una larga lista de operaciones sobre los datos, en forma de procesadores:
- Interacción con fuentes de datos. Carga de datos desde, y hacia, una amplia variedad de formatos y tecnologías: HDFS, ElasticSearch, FTP, bases de datos SQL, MongoDB, ficheros… entre otros muchos.
- Conversión de datos. Cambios de estructura de la informacion, de y hacia JSON, XML, Avro, CSV, etc.
- Proceso de la información. Operaciones de unión y división de los datos, así como su validación y transformación.
- Delegación de funcionalidades. Procesadores que pueden traspasar datos a otros sistemas de procesamiento, para realizar tareas sobre ellos, que ya estén implementadas en otros sistemas: Por ejemplo, loa comunicación bidireccional con un tercero, mediante colas Kafka, o la ejecución transparente de procesos de Apache Flume.
Para casos específicos en los que el tratamiento del dato requiera algo ad hoc, NiFi proporciona un mecanismo para integrar un proceso definido en una simple clase java, como un procesador más dentro del diseño del flujo.
Ejecución en clúster
Para garantizar un óptimo rendimiento, la ejecución del proceso definido en este árbol, se puede realizar en paralelo: Varias máquinas en las que NiFi esté en ejecución colaboran para realizar las operaciones definidas en uno de ellos.
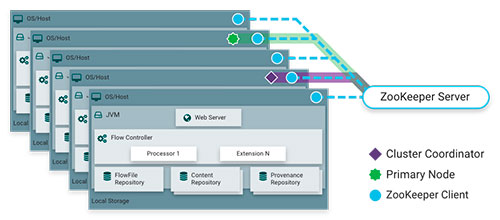
Esta ejecución se programa dentro del interfaz web de NiFi, ya sea a intervalos de tiempo, o mediante una máscara crontab.Dentro de las opciones de ejecución, tenemos MiNiFi, un proyecto derivado de NiFi, que nos proporciona un runtime con bajos requerimientos, para ejecutar flujos definidos y exportados desde NiFi, conservando los recursos de la máquina en la que se ejecuta el proceso.
Un paso mas allá del ETL
Tras este primer contacto con Apache NiFi, podemos darnos cuenta de que por la sencillez de su uso (integrado por completo en una aplicación web), y la potencia de sus capacidades (con flujos complejos de procesadores, proporcionados o creados a medida) es una herramienta muy a tener en cuenta para el traspaso de datos entre sistemas.











