

Etimología y definición
En general la etimología de la red neuronal, tal y como vimos en el capítulo anterior “Redes Neuronales y Deep Learning. Capítulo 1: Preludio”, viene inspirada por las redes neuronales biológicas que forman parte del cerebro humano. En este sentido, el paralelismo es directo entre las neuronas de una red neuronal artificial y las de una red biológica. Las primeras se conectan entre sí mediante enlaces, de la misma forma que las segundas lo hacen mediante la sinapsis.
Como aprendimos anteriormente, una red neuronal se basa en la interacción de muchas partes simples trabajando conjuntamente para obtener un resultado que puede ser más o menos abstracto según la complejidad de la red. Es a cada una de esas partes simples a lo que llamamos neurona. Es decir, una neurona es la unidad básica de información de una red neuronal. A continuación hablaremos del papel que juega la neurona dentro de la red e introduciremos una noción fundamental como es el de la función de activación.
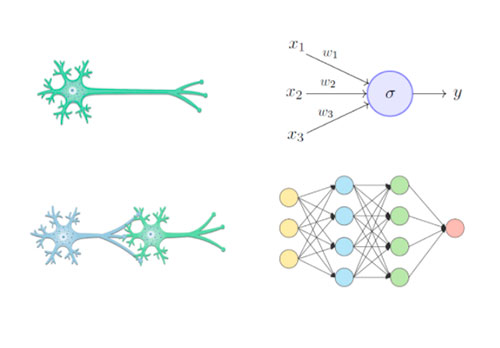
Papel de la neurona dentro de la red neuronal
Desde un enfoque muy básico, el funcionamiento de una neurona se basa en recibir unos valores numéricos de entrada, combinarlos, y devolver un valor numérico de salida. Entonces, en primera instancia, podemos ver una neurona como una función matemática de la siguiente manera:
Donde:
- y es el valor de salida.
- x1,…,xn son los valores de entrada.
- w1,…,wn se denominan pesos o parámetros, y miden la influencia de cada valor de entrada en el resultado final.
- b intercepto o bias se trata de un parámetro adicional para que la función no esté condicionada a pasar por el origen, permitiendo de esta manera un mayor ajuste a la realidad.
Llegados a este punto, podemos pensar que una neurona es exactamente lo mismo que una regresión lineal. Realmente esto es cierto, y el comportamiento es análogo de momento. Sin embargo, hay un elemento que juega un papel fundamental en las neuronas artificiales pero que en cambio no está presente en una regresión lineal. Se trata de la función de activación y hablaremos de ella en el siguiente apartado.
Función de activación de la neurona
Para poner en valor la importancia de las funciones de activación vamos a ver dos ejemplos a continuación.
En primer lugar supongamos que tenemos la distribución de puntos de la siguiente imagen y queremos separar los rojos de los azules.
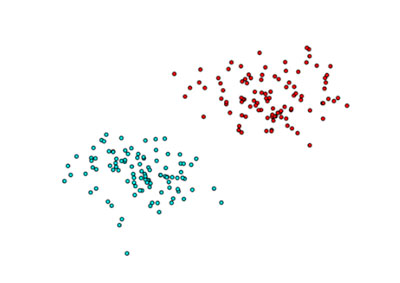
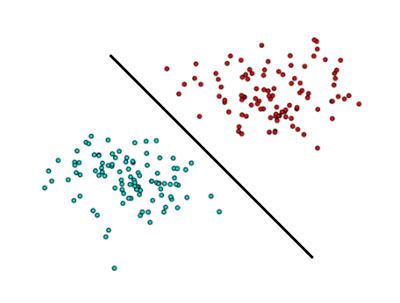
Como podemos observar en la imagen de abajo, es fácil encontrar una de las infinitas funciones que permiten separar estos dos grupos linealmente. Por tanto, una única neurona bastaría en este caso para realizar la clasificación de nuestras observaciones. Este problema se conoce en lógica como puerta del tipo AND o del tipo OR.
Bien, el siguiente paso sería suponer la distribución que vemos a continuación. Podemos tomar la imagen de la izquierda y tratar de separar los puntos en azules y rojos con una única función lineal, pero nos será imposible. En cambio, tal y como vemos a la derecha, combinando dos funciones es fácil realizar la separación. Es por ello que decimos que combinando dos neuronas podemos resolver lo que se conoce en lógica como puerta XOR.

Por último supongamos que ahora los puntos se distribuyen de esta última forma.

Podemos intentarlo, pero nunca encontraremos una función lineal que separe ambas clases. De la misma manera tampoco encontraremos una combinación de las mismas como hicimos en el paso anterior. En este problema necesitamos hacer usos de funciones no lineales tal y como vemos en la imagen de la derecha.
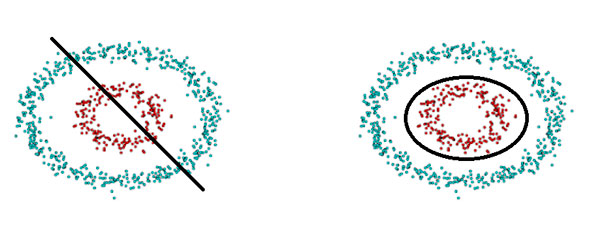
Con el objetivo de poder llegar a construir este tipo de fronteras necesitamos hacer uso de funciones de activación. El uso de estas funciones se resume en distorsionar el valor de salida de la suma ponderada, de tal forma que volviendo a la fórmula que vimos anteriormente ahora podemos ver una neurona como
Donde la función f es nuestra función de activación. De hecho, gracias a las funciones de activación tenemos el siguiente teorema que demostró por primera vez Moshe Leshno en 1993 y que es de vital importancia en este campo.
Teorema de aproximación universal: Bajo una serie de hipótesis, cualquier función continua f puede ser modelada por medio de una red neuronal que conste de una capa oculta y el suficiente número de neuronas.
Función de activación: Estado del arte.
A continuación presentaremos las funciones más usadas, así como una pequeña descripción de cada una de ellas.
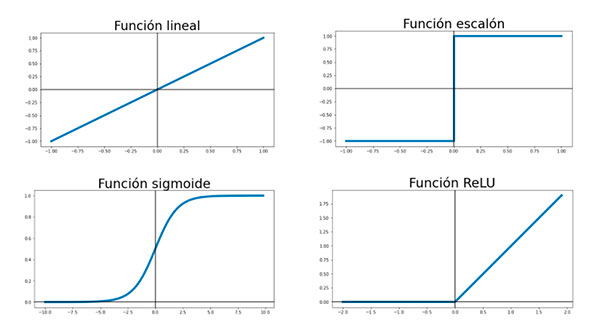
- Función lineal. Se trata de la función identidad. Esta función hace que la salida sea igual a la entrada. Si la función de activación es esta, entonces esa neurona se comporta exactamente igual que una regresión lineal.
- Función escalón. Útil cuando la salida es categórica y se pretende clasificar. Sin embargo, en la práctica no es muy utilizada debido a que el escalón hace que sea difícil trabajar con su derivada.
- Función sigmoide. Resulta muy interesante porque gracias a ella los valores muy grandes convergen a 1 y los valores muy pequeños a -1, por lo que sirve para representar probabilidades. Tiene un inconveniente y es que su rango no está centrado en el origen. No obstante, este último problema podemos solventarlo usando la función tangente hiperbólica, que resulta muy similar.
- Función ReLU (unidad rectificada lineal). Se trata de una de las funciones de activación más utilizadas. Se comporta como una función constante para valores negativos y como una función lineal para valores positivos.
Añadiendo estas deformaciones no lineales el problema de encadenar varias neuronas queda solventado. Por ejemplo, combinando un número suficiente neuronas con función sigmoide podemos obtener superficies como las siguientes:
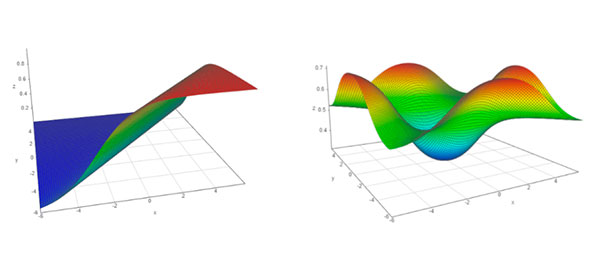
Podemos observar que la intersección de esta segunda superficie con el plano genera la frontera necesaria para hacer la clasificación de los puntos con distribución de circunferencias concéntricas que vimos anteriormente.
Una vez hemos visto el potencial de las redes neuronales y cómo funcionan las neuronas estamos en disposición de ver qué mecanismos utilizan para automatizar el aprendizaje. Pero ¡eso será en el próximo capítulo!












