

In the previous article "Machine Learning: Origins and Evolution", we mentioned that in Future Space we have had several opportunities to use Machine Learning. This time we work in the health sector, predicting absenteeism from several companies.
Absenteeism
Absenteeism from work is any absence or abandonment of the job and the duties attached to it. And this entails a failure to comply with the conditions established in the employment contract.
Absenteeism is one of the issues that most concerns companies because of the organizational problems it raises and the costs it generates.
During 2018, 753,000 employees did not go to work a single day of the year, according to the 8th Adecco Report on Absenteeism. This data, compiled by the Adecco Group Institute, puts the absenteeism rate at 5.3%. This translates into some 1.35 billion hours per year lost due to absences from work.
The total cost of absenteeism in 2018 amounted to more than 85 billion euros. This represented an increase of 10% over the previous year. In addition, it had a direct cost to companies of almost 7 billion euro. And an opportunity cost of more than 70 billion euro for companies.
Absenteeism factors
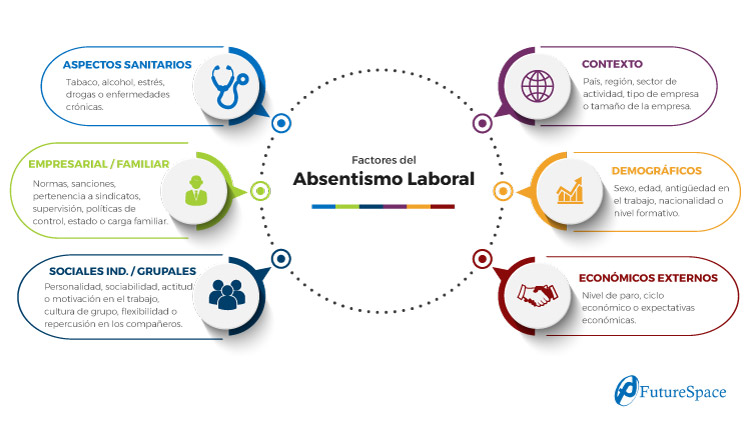
Absenteeism depends on multiple factors, some more objective:
- Demographics: sex, age, seniority at work, nationality or educational level
- External economic: level of unemployment, economic cycle or economic expectations.
- Business: position, salary or type of job.
- Family situation: marital status or family responsibilities.
- Health aspects: tobacco, alcohol, stress, drugs or chronic diseases.
- Context: country, region, sector of activity, type of company or size of company
And other factors, much more subjective and difficult to measure, but equally important all of them:
- Individual social: personality, sociability, attitude or motivation at work.
- Group socials: group culture, flexibility or peer impact.
- Business: company rules, sanctions, union membership, supervision and control policies.
So taking into account all these factors, we at Future Space set out to predict absenteeism from two points of view. On the one hand, the number of sick leave, which includes the total number of cases pending medical discharge during the current month. On the other hand, the cost of sick leave, which includes the total amount of cases pending medical discharge during the month under study.
Engineering of variables in Machine Learning
We have already understood both the sector and the data available to us to predict absenteeism. A crucial phase in data analysis projects is now needed. This is the creation of the input data set for the Machine Learning model.
So far, we have a lot of data about:
- workers (age, sex or nationality),
- the employment relationship (length of service, type of contract or type of working day) and
- the contingencies that have occurred in the company (dates of leave and discharge, type of contingency, cause of leave, relapses, degree of injury or reason for discharge)
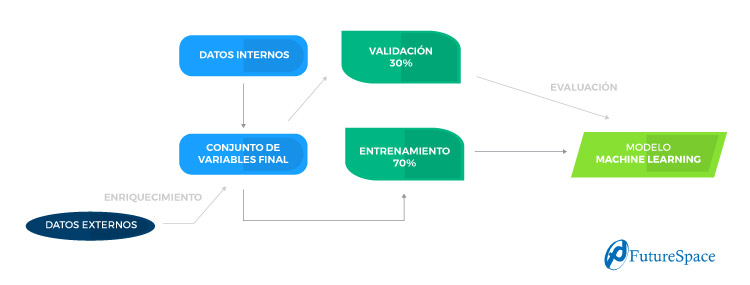
This data largely explains the absenteeism situation. But if we consider only the internal data of the company we will not collect the external economic or contextual behaviors. Therefore, it is always advisable to evaluate the possibility of capturing external data that can enrich the company's internal data.
In addition, in this way, we make it possible to improve the performance of predictive models. Some of the variables used in the enrichment have been the CPI, average salaries, unemployment and employment rates or the unemployed population.
At this point it is necessary to consider the need to calculate certain variables from those already available. We can create them by means of calculations or groupings of them, so that they provide more information to the predictive models. These variables can be temporary, company holidays or holiday periods.
Timing of absenteeism
As we have already seen, absenteeism from work has a markedly temporary character. This has been included in part thanks to economic and time variables. But the model needs to anticipate what is going to happen, i.e. to be one step ahead of the workers in predicting absenteeism.
And in order to provide predictive models with this knowledge, it is necessary to create delayed variables. Delays consist of considering the variables at other times in time: the previous day, the previous week or the previous month.
In this way, the delay of one day allows the model to know the magnitude of the previous day. And the rest of the delays allow the model to know the behavior of that same day a few weeks ago.
Advantages of the Machine Learning models
At this point, we have already created the dataset that will be the input to the models that predict the absenteeism. But why have we decided to predict absenteeism using Machine Learning?
Let's find out what the advantages of the Machine Learning models are compared to the classic models. Historically, time series have been studied from a stochastic (statistical) point of view. These models are based on extracting the different components that make up a time series. These are trend, seasonal variations (punctual periods), cyclical variations (periods that repeat over time) and a random or irregular part.
Generally, these models focus on the time series to be estimated, its delays and time variables that allow detecting seasonal and/or cyclical variations. However, Machine Learning models allow us to predict the behavior of the time series taking into account many more variables.
In addition, due to Machine Learning's own algorithms they are able to detect interactions between variables as well as linear and non-linear relationships. While classical models are not capable of detecting interactions between variables unless they are known a priori and introduced as a variable.
How are Machine Learning models created?
For a model to be able to predict absenteeism, it must be trained. That is, let it learn by itself with the data set we have prepared.
In this process it is necessary to separate the data set into two groups, one containing 70% of the total and the other containing the remaining 30%. We will call the first one a training set, while the second one will be called a validation set.
So we will only let the model learn with the training set. And we'll use the validation set to evaluate how good or bad our model is.
We do this so that the model does not reach a point where it can only predict what it has seen before. In this way we give it a certain intelligence to predict cases that it has not seen before but are similar to those it has learned. And in this way, we avoid what is known as 'overfitting' the model.
You want to predict the future? Use data and Machine Learning
Society generates an enormous amount of information every day, the power of computers is advancing at a frightening pace. And every year new Machine Learning algorithms are discovered that allow us to extract all the juice from the data.
According to the research company IDC, by 2025 we will be generating 463 trillion (yes, yes! 18 zeros!) bytes of information every day. Let's not miss out on this great opportunity, and use the data to predict the future!








