

En el artículo anterior “Machine Learning: Los orígenes y la evolución”, mencionamos que en Future Space hemos tenido diversas oportunidades de utilizar el Machine Learning . En esta ocasión trabajamos en el sector de la salud, prediciendo el absentismo laboral de varias compañías.
Absentismo laboral
El absentismo laboral es toda aquella ausencia o abandono del puesto de trabajo y de los deberes anexos al mismo. Y esto conlleva un incumpliendo de las condiciones establecidas en el contrato de trabajo.
El absentismo es una de las cuestiones que más preocupan a las empresas por los problemas organizativos que suscita y los costes que genera.
Durante 2018 no acudieron ni un solo día del año a su puesto de trabajo 753.000 asalariados, según el VIII Informe Adecco sobre Absentismo. Estos datos recopilados por el Adecco Group Institute sitúan la tasa de absentismo en un 5,3%. Lo que se traduce en unas 1.350 millones de horas al año que se pierden por ausencias al puesto de trabajo.
El coste total del absentismo ascendió en 2018 a más de 85.000 millones de euros. Lo que supuso un incremento del 10% con respecto al ejercicio anterior. Además, para las empresas tuvo un coste directo de casi 7.000 millones de euros. Y un coste de oportunidad que supuso más de 70.000 millones de euros para las empresas.
Factores del absentismo laboral
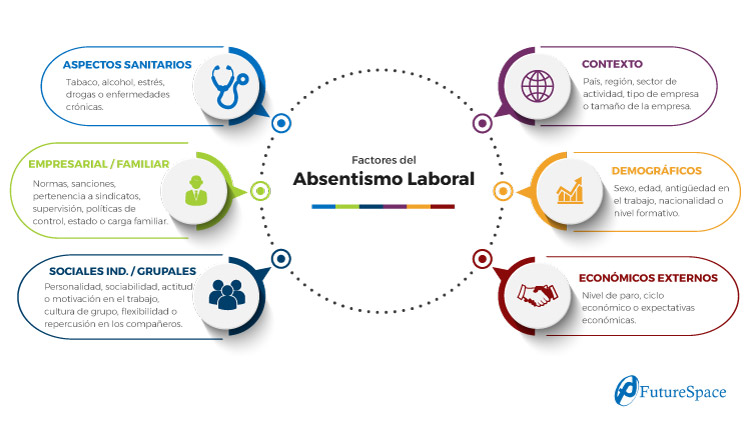
El absentismo laboral depende de múltiples factores, algunos más objetivos:
- Demográficos: sexo, edad, antigüedad en el trabajo, nacionalidad o nivel formativo.
- Económicos externos: nivel de paro, ciclo económico o expectativas económicas.
- Empresarial: cargo, salario o tipo del puesto de trabajo.
- Situación familiar: estado civil o cargas familiares.
- Aspectos sanitarios: tabaco, alcohol, estrés, drogas o enfermedades crónicas.
- Contexto: país, región, sector de actividad, tipo de empresa o tamaño de la empresa.
Y otros factores, mucho más subjetivos y más difíciles de medir, pero igual de importantes todos ellos:
- Sociales individuales: personalidad, sociabilidad, actitud o motivación en el trabajo.
- Sociales grupales: cultura de grupo, flexibilidad o repercusión en los compañeros.
- Empresariales: normas de la empresa, sanciones, pertenencia a sindicatos, supervisión y políticas de control.
Así que teniendo en cuenta todos estos factores, desde Future Space nos propusimos predecir el absentismo laboral desde dos puntos de vista. Por un lado, el número de bajas, que recoge el total de casos pendientes de alta médica durante el mes en curso. Y por otro lado, el coste de las bajas, que recoge el importe total que suponen todos los casos pendientes de alta médica durante el mes de estudio.
Ingeniería de variables en Machine Learning
Ya hemos entendido tanto el sector como los datos de los que disponemos para predecir el absentismo laboral. Ahora es necesario realizar una fase crucial en los proyectos de analítica de datos. Esta es la creación del conjunto de datos de entrada para el modelo de Machine Learning.
Hasta ahora, disponemos de gran cantidad de datos acerca de:
- los trabajadores (edad, sexo o nacionalidad),
- la relación laboral (antigüedad laboral, tipo de contrato o tipo de jornada) y
- las contingencias ocurridas en la empresa (fechas de baja y alta, tipo de contingencia, causa de la baja, recaídas, grado de la lesión o motivo de alta).
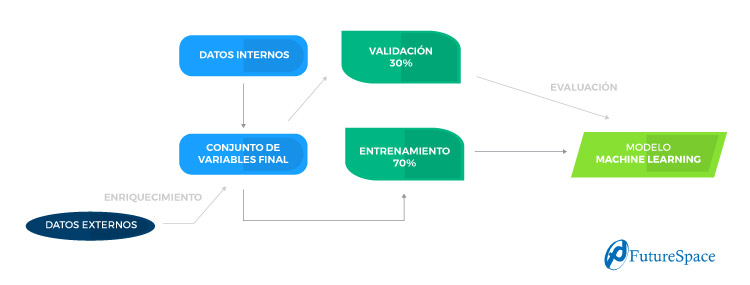
Estos datos explican en gran parte la situación de absentismo laboral. Pero si consideramos únicamente los datos internos de la compañía no recogeremos los comportamientos económicos externos o de contexto. Por lo que siempre es recomendable evaluar la posibilidad de capturar datos externos que puedan enriquecer los datos internos de la compañía.
Además, de esta forma, posibilitamos la mejora del rendimiento de los modelos predictivos. Algunas de las variables utilizadas en el enriquecimiento han sido el IPC, los salarios medios, las tasas de paro y empleo o la población parada.
Llegados a este punto es necesario plantearse la necesidad de calcular ciertas variables a partir de las que ya disponemos. Podemos crearlas mediante cálculos o agrupaciones de las mismas, de forma que aporten más información a los modelos predictivos. Estas variables pueden ser temporales, festivos de la empresa o épocas vacacionales.
Temporalidad del absentismo laboral
Como ya hemos visto, el absentismo laboral posee un marcado carácter temporal. El cual ha sido incluido en parte gracias a las variables económicas y temporales. Pero el modelo necesita adelantarse a lo que va a ocurrir, es decir, ir un paso por delante de los trabajadores para predecir el absentismo laboral.
Y con el objetivo de dotar a los modelos predictivos de este conocimiento, es necesaria la creación de variables retardadas. Los retardos consisten en considerar las variables en otros momentos temporales: día anterior, semana anterior o el mes anterior.
De esta forma, el retardo de un día permite al modelo conocer la magnitud del día anterior. Y el resto de los retardos permiten conocer el comportamiento de ese mismo día hace unas semanas.
Ventajas de los modelos de Machine Learning
En este punto, ya tenemos creado el conjunto de datos que será la entrada a los modelos que predigan el absentismo laboral. Pero ¿por qué hemos decidido predecir el absentismo laboral mediante Machine Learning?
Vamos a conocer cuales son las ventajas de los modelos de Machine Learning con respecto a los modelos clásicos. Históricamente, las series temporales se han estudiado desde un punto de vista estocástico (estadístico). Estos modelos se basan en extraer las diferentes componentes que conforman una serie temporal. Las cuales son tendencia, variaciones estacionales (períodos puntuales), variaciones cíclicas (períodos que se repiten a lo largo del tiempo) y una parte aleatoria o irregular.
Generalmente, estos modelos se focalizan en la serie temporal a estimar, retardos de la misma y variables temporales que permiten detectar las variaciones estacionales y/o cíclicas. Sin embargo, los modelos de Machine Learning permiten predecir el comportamiento de la serie temporal teniendo en cuenta muchas más variables.
Además, debido a los propios algoritmos de Machine Learning estos son capaces de detectar interacciones entre las variables además de relaciones lineales y no lineales. Mientras que los modelos clásicos no son capaces de detectar interacciones entre las variables a menos que se conozcan a priori y sean introducidas en forma de variable.
¿Cómo se crean los modelos de Machine Learning?
Para que un modelo sea capaz de predecir el absentismo laboral, es necesario entrenarlo. Es decir, dejarle que aprenda por sí mismo con el conjunto de datos que hemos preparado.
En este proceso es necesario separar el conjunto de datos en dos grupos, uno contendrá un 70% del total y el otro contendrá el 30% restante. Al primero lo llamaremos conjunto de entrenamiento, mientras que al segundo lo llamaremos conjunto de validación.
De manera que al modelo sólo le dejaremos aprender con el conjunto de entrenamiento. Y utilizaremos el conjunto de validación para evaluar cómo de bueno o malo es nuestro modelo.
Esto lo hacemos para que el modelo no llegue a un punto en el que sólo sepa predecir aquello que ha visto con anterioridad. Así le dotamos de cierta inteligencia para predecir casos que no ha visto anteriormente pero son similares a los aprendidos. Y de esta forma, evitamos lo que se conoce como sobreentrenamiento (‘overfitting’) del modelo.
¿Quieres predecir el futuro? Usa datos y Machine Learning
La sociedad genera cada día una cantidad ingente de información, la potencia de los ordenadores avanza a un ritmo estremecedor. Y cada año se descubren nuevos algoritmos de Machine Learning que nos permiten extraer todo el jugo a los datos.
Según la empresa de investigación IDC, en 2025 estaremos generando 463 trillones (¡sí, sí! ¡18 ceros!) de bytes de información cada día. No dejemos de lado esta gran oportunidad que se nos presenta, y ¡usemos los datos para predecir el futuro!











