

El flujo de datos descrito en este artículo hace uso del procesador RemoveMetadata, desarrollado desde cero en la publicación anterior, Apache Nifi: Validando transferencias de ficheros.
Arrancar Apache NiFi
Una vez que hemos acabado el desarrollo, necesitamos disponer de una instalación de NiFi en la que construir nuestro flujo de trabajo. Los pasos para arrancar en un entorno Linux están disponibles aquí, para Windows, son los siguientes:
- Descargamos Apache NiFi (disponible aquí)
- Descomprimimos el fichero
- Accedemos a la carpeta bin
- Ejecutamos run-nifi.bat
- Accedemos, a través del navegador, a la dirección http://localhost:8080/nifi
Crear flujo de trabajo
Desarrollo del lector de configuración
La lectura de las propiedades del fichero XML, se hace independiente al resto del flujo, para que se ejecute una vez y queden almacenadas en memoria.
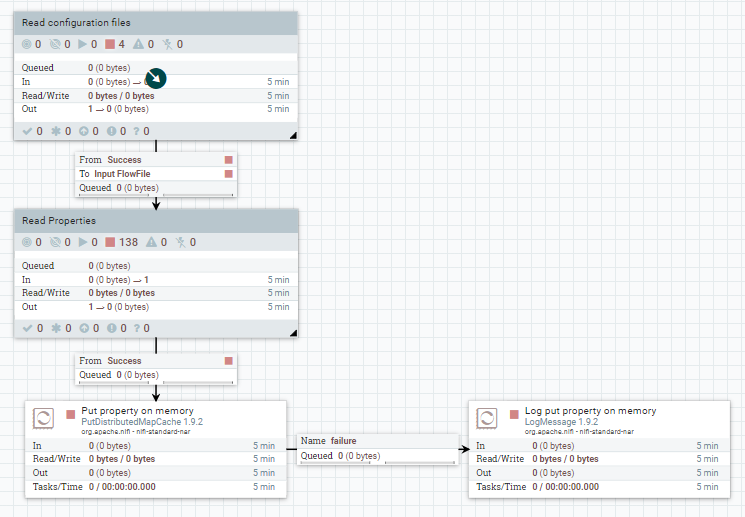
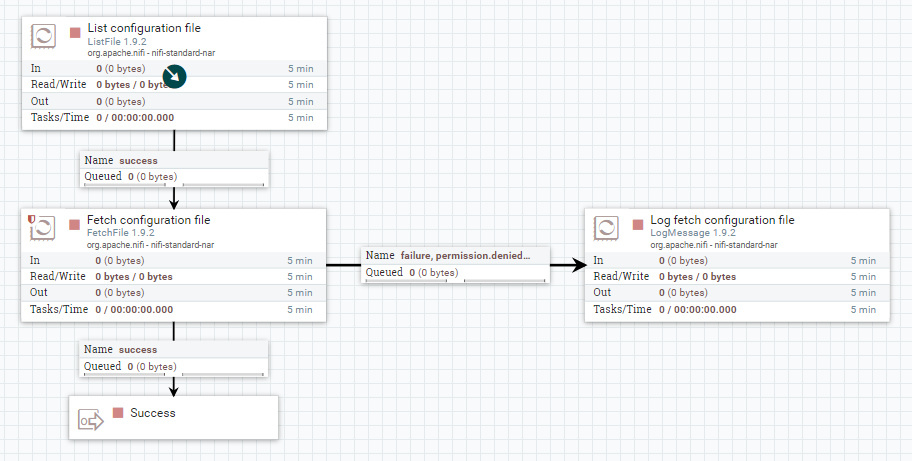
Este flujo consiste en la lectura de uno o varios ficheros de configuración XML, a través de los procesadores ListFile y FetchFile. Estos listan y consumen los ficheros, respectivamente.
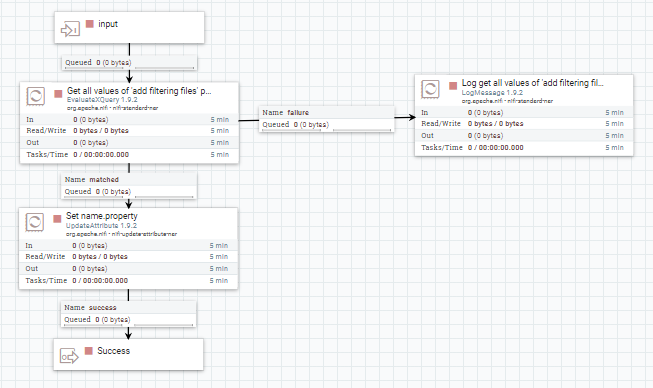
Posteriormente, se extrae el valor de cada propiedad y se define una clave para almacenarla en memoria. Esto se hace utilizando:
- El procesador EvaluateXQuery, configurado con el xPath de la propiedad a extraer.
- El procesador UpdateAttribute: Se crea un nuevo atributo, name.property, cuyo valor será la clave con la que se almacene la propiedad de configuración.
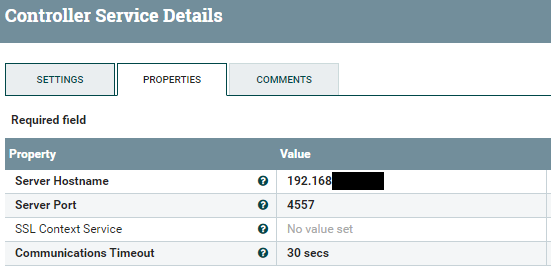
Finalmente, con el procesador PutDistributedMapCache se graban las propiedades en memoria, haciendo uso del controlador DistributedMapCacheClientService.
Durante todo el flujo, se incorporan procesadores LogMessage que escriben trazas de log personalizadas. Por defecto, el fichero que registran es nifi-app.log.
Desarrollo del resto del flujo en NiFi
El último paso, una vez tenemos disponibles todos los elementos necesarios para este flujo, es llevar a cabo su desarrollo en NiFi.
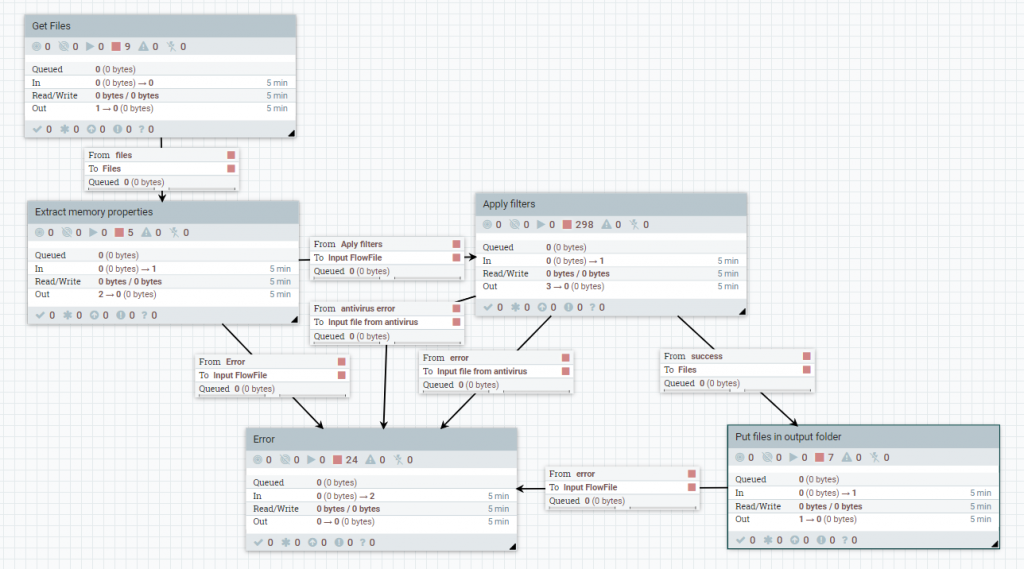
El flujo comienza obteniendo los ficheros de carpetas locales o por conexiones FTP, con los procesadores GetFile y GetFTP, respectivamente.
Estos procesadores están configurados para que sean ejecutados solo por el nodo primario del cluster, para evitar errores de accesos concurrentes. Justo después de su ejecución, se balancea la carga entre todos los nodos, ya que la relación success está configurada como RoudRobin.
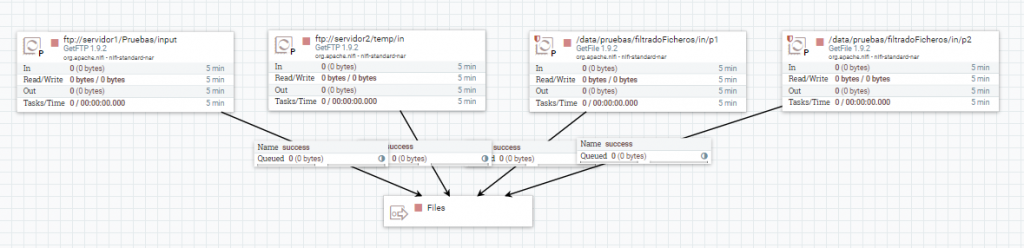
Posteriormente se leen las propiedades que están almacenadas en memoria. Para ello, se utiliza el procesador LookupAttribute, que agrega un nuevo atributo al flowfile con el valor obtenido.
Este procesador utiliza el controlador DistributedMapCacheLookupService, el cual está configurado con un controlador de tipo DistributedMapCacheClientService. Este último será el que use el procesador PutDistributedMapCache que graba las propiedades en memoria.
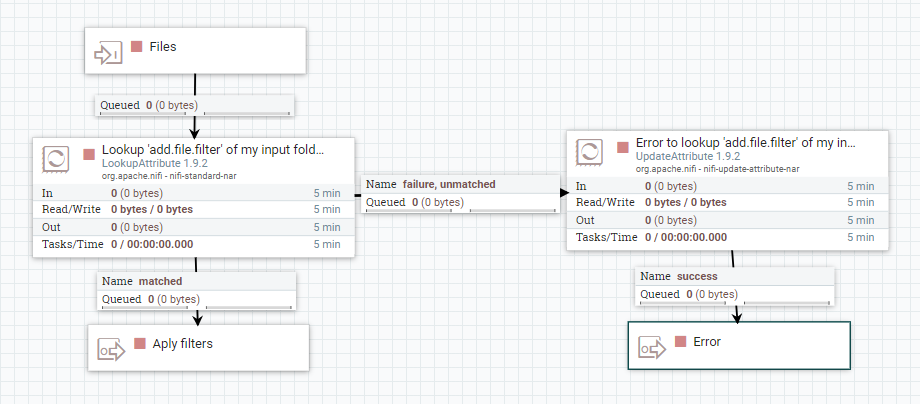
El siguiente paso es ejecutar las validaciones y transformaciones sobre el fichero.
Lo primero que se hace es comprobar, con el procesador RouteOnAttribute, si la propiedad asociada está a true. Esto se realiza antes de ejecutar cualquiera de los grupos de procesadores y en caso afirmativo, se ejecutará cada uno de ellos.
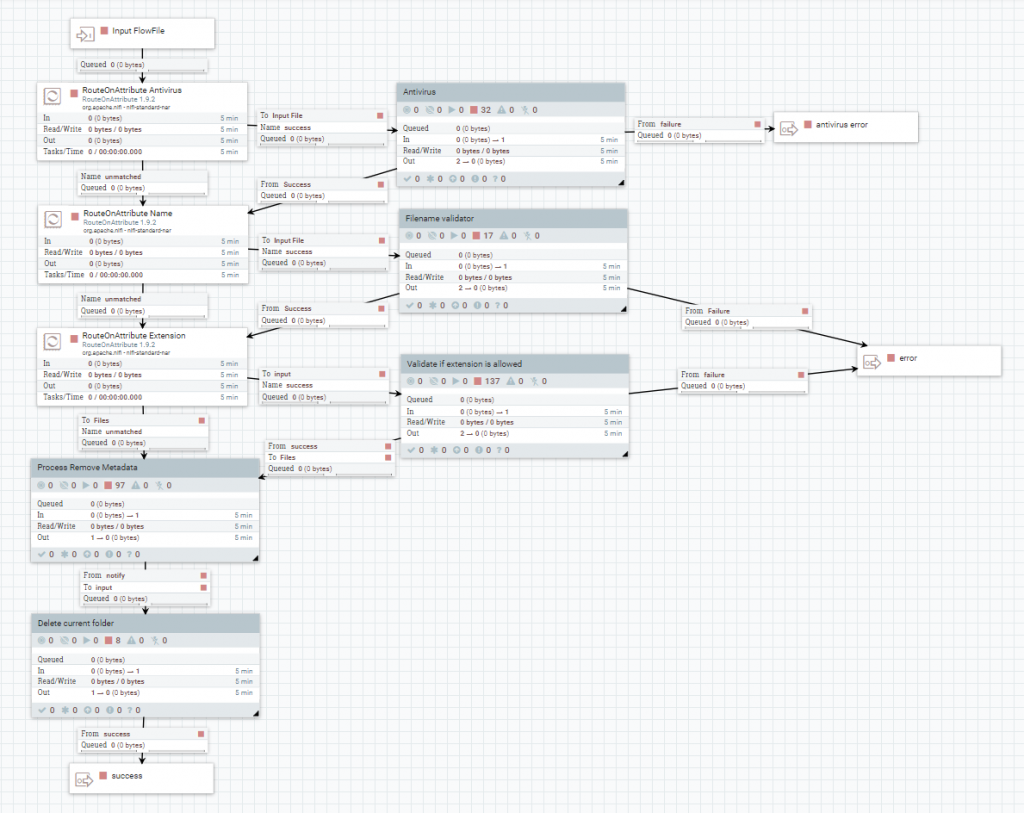
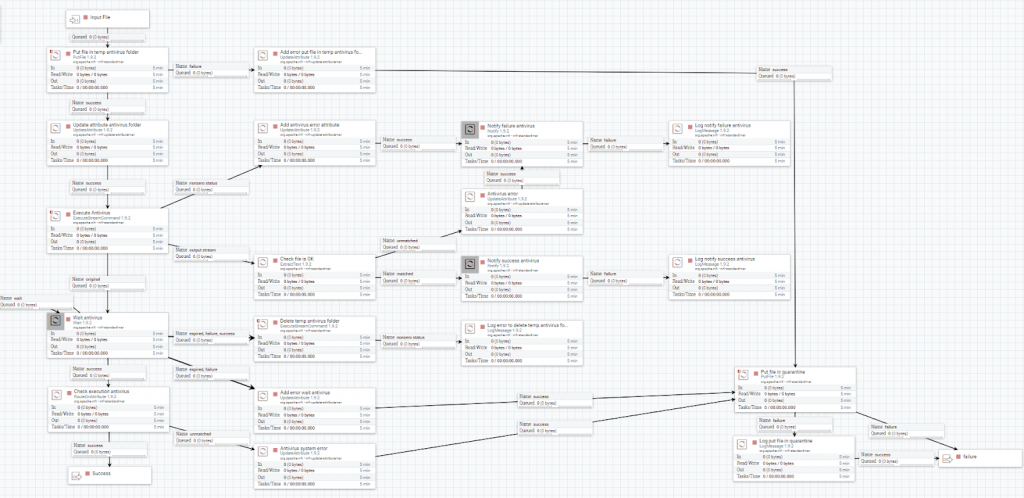
Antivirus
Se escribe el fichero en una carpeta temporal, accesible por McAfee, con el procesador PutFile.
Se ejecuta la aplicación de antivirus por línea de comandos, con el procesador ExecuteStreamCommand. Además, se deja el flowfile original en un procesador Wait, y se notifica la salida de la consola con los procesadores Notify.
Si cualquiera de los procesadores Notify fallan al ejecutarse, se graba un registro en el fichero de log, con el procesador LogMessage.
Finalmente, si la respuesta no ha sido ‘OK’, se escribe el fichero en una carpeta de auditoría y se procesa el error.
Validador de nombres
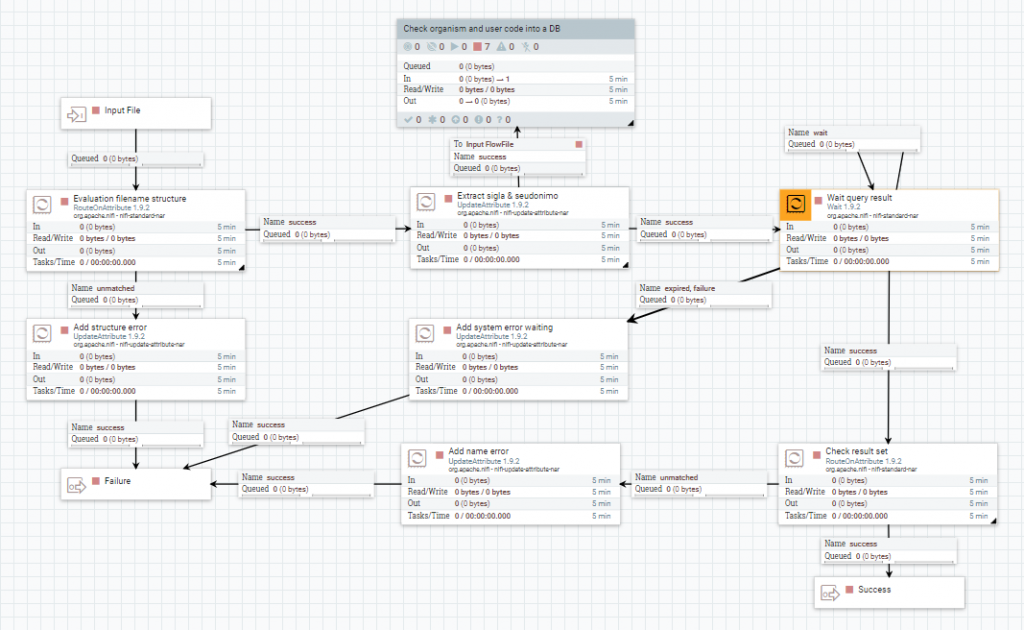
El primer nivel de validación, se realiza con un procesador RouteOnAttribute, que comprueba si el nombre del fichero tiene la estructura ‘YY-XX-ZZ’. Si no es el caso, se agrega un nuevo atributo ‘message.error’ con el procesador UpdateAttribute y se procesa el error.
Si cumple esta condición, se extraerán la primera y segunda partícula. Después, se dejará el flowfile original esperando, con el procesador Wait, a que se ejecute la consulta en la base de datos.
Una vez que el grupo de procesadores notifica el resultado de la consulta, si su valor no es ‘OK’ se procesa el error.
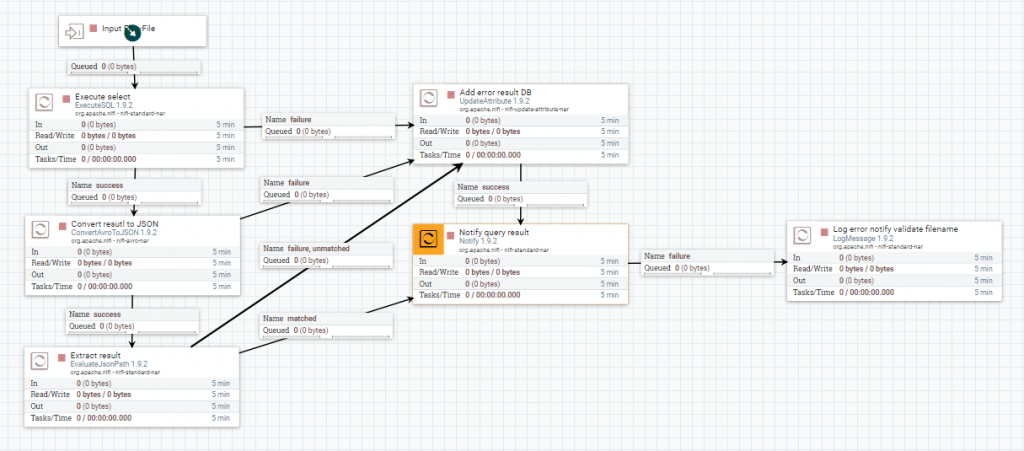
Consulta a base de datos
Se ejecuta la select con el procesador ExecuteSQL, después se convierte el resultado a JSON con el procesador ConvertAvroToJSON, y se extrae el resultado con el procesador EvaluateJsonPath.
Por último, con el procesador Notify, se notifica este resultado al flowfile original que está ejecutando el procesador Wait anterior.
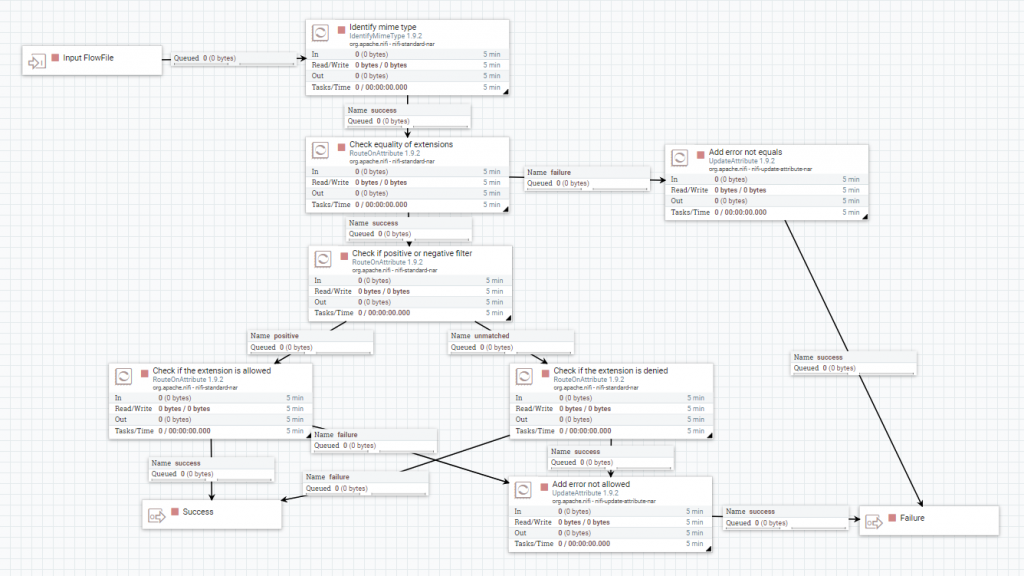
Extensiones
Para extraer la extensión real del fichero procesado, se utiliza el procesador IdentifyMimeType. Seguidamente, se comprueba si el valor extraído se corresponde con la extensión que tiene el fichero en su nombre, con el procesador RouteOnAttribute.
Posteriormente, se distingue si debes comprobar las extensiones permitidas o denegadas, con el procesador RouteOnAttribute. En el primer caso se valida que la extensión del fichero esté registrada entre las configuradas y en el segundo caso, que no lo esté.
Metadatos
Primero, se escribe el fichero en una carpeta temporal con el procesador PutFile. Segundo, se agrega como atributo del flowfile esta ruta utilizando el procesador UpdateAttribute. Por último, se eliminan los metadatos del fichero con el procesador RemoveMetadata.
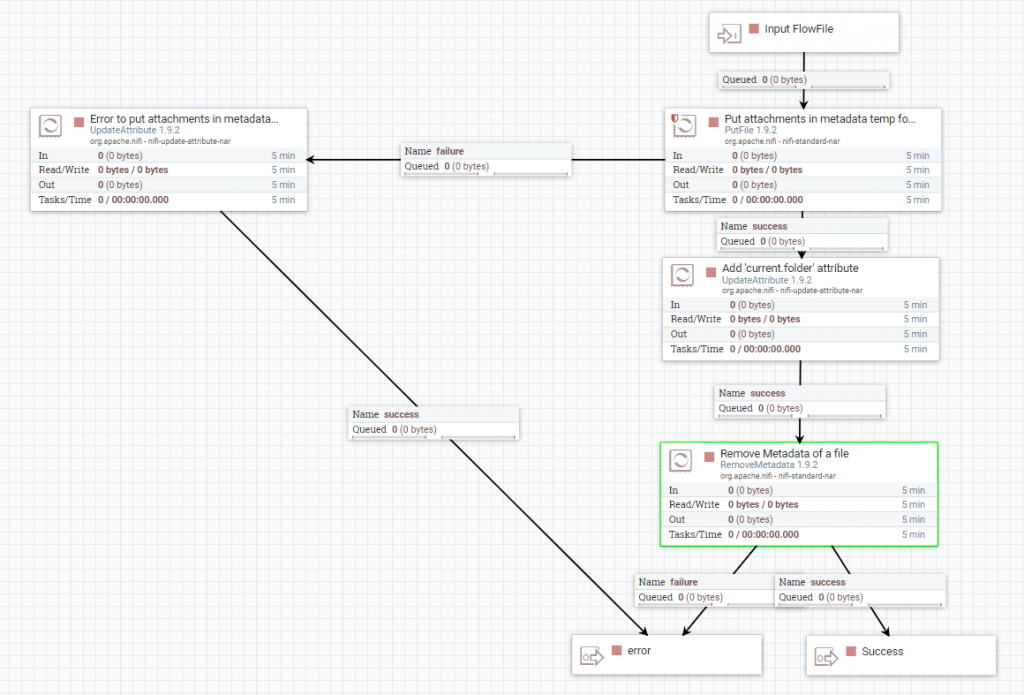
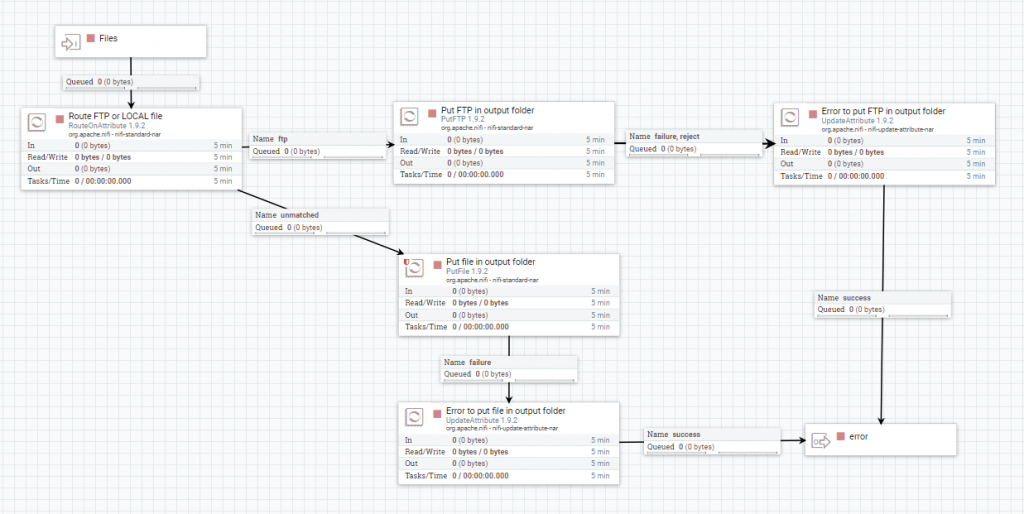
Finalmente, si el procesamiento del fichero acaba con éxito:
- se comprueba, con el procesador RouteOnAttribute, si la salida es local o FTP
- Se escribe el fichero en su ruta de destino, con los procesadores PutFile o PutFTP.
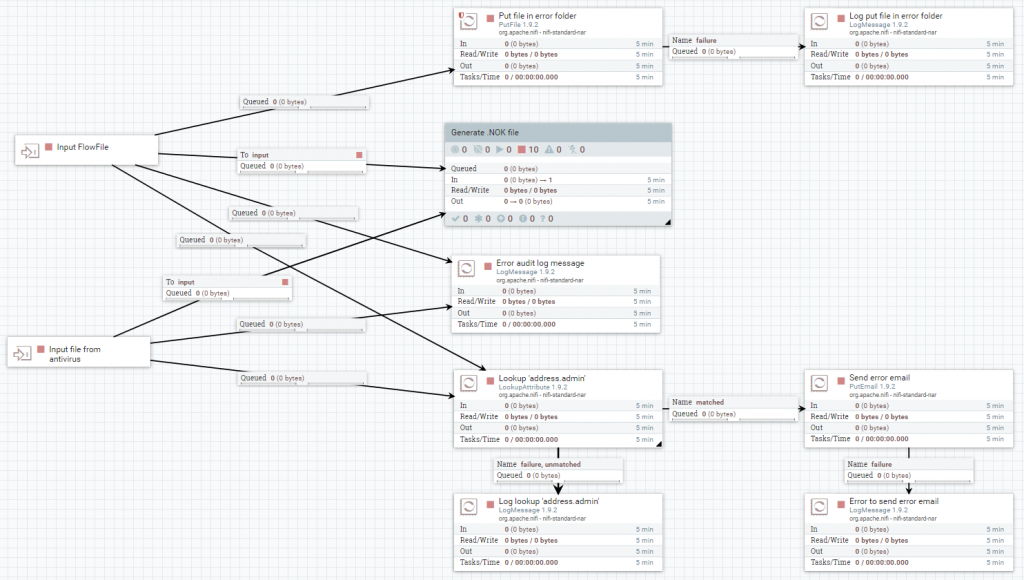
Si por el contrario, se produce algún error durante el proceso, se deja un registro en el fichero de log, con el procesador LogMessage. También, se genera un fichero ‘.NOK.txt’, ambos con el contenido de la propiedad ‘message.error’. Además, se busca la dirección de correo del administrador en memoria, con el procesador LookupAttribute y se le envía un correo utilizando el procesador PutEmail.
Finalmente, solo si el error no viene del grupo de procesadores Antivirus, se escribirá el fichero en una ruta de error, con el procesador PutFile.
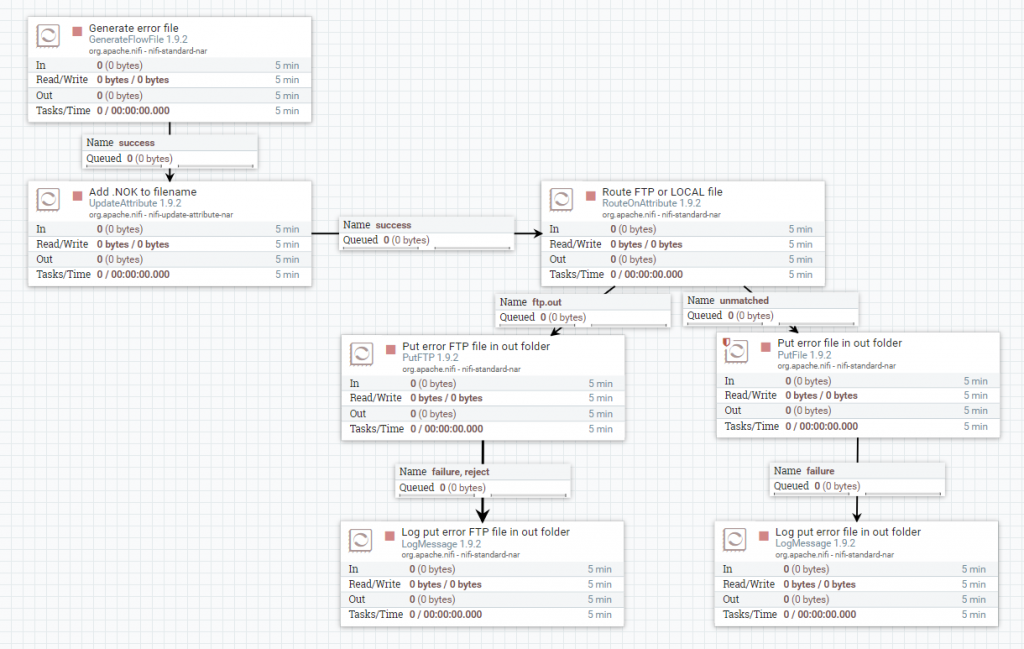
Generar fichero .NOK.txt
Se genera un fichero con el contenido del atributo ‘message.error’, utilizando el procesador GenerateFlowFile. Luego, se le asigna el mismo nombre que el fichero original, pero con extensión ‘.NOK.txt’, con el procesador UpdateAttribute.
Después, se comprueba, con el procesador RouteOnAttribute, si la salida es local o FTP, para escribir el fichero en la ruta de destino con los procesadores PutFile o PutFTP, respectivamente.
Y con esto, acabaríamos todo el proceso.












