

Hace unas semanas tuve la oportunidad de participar como ponente en el “III Foro Anual de Gestión de Siniestros y Fraude” organizado por INESE en la que pude explicar cómo la analítica de grafos puede ayudar en la detección de fraude aportando nuevas perspectivas de análisis. En esta serie de posts me gustaría poder entrar en los detalles de cómo las compañías aseguradoras pueden emprender el “roadmap de la detección” desde la tramitación manual a la analítica de grafos pasando por la implementación de algoritmos de Machine Learning. Estas son las fases del “Roadmap de la detección”:
Matrices de fraude o automatización de reglas de negocio
La mayor parte de las compañías disponen de una identificación clara de las reglas de negocio que determinan el riesgo de un determinado siniestro en función de la experiencia de negocio adquirida en los últimos años.
De esta forma, las compañías determinan el riesgo de un siniestro en base a las condiciones establecidas en el producto contratado (periodos de carencia, exclusiones, etc…) o bien, en función de la experiencia ganada con siniestros sospechosos en el pasado, identificando una serie de reglas que permiten obtener un indicador de riesgo en base al cumplimiento de dichas reglas.
Algunas compañías han pasado de la identificación de las reglas de negocio o matriz de fraude, a una automatización de la misma basada en productos de mercado o bien, en una implementación ad-hoc para sus sistemas de tramitación de siniestros.
- La automatización de la matriz de fraude aporta una serie de ventajas:
- Permite que el modo de tramitación de todo el departamento se base en las mismas reglas evitando la interpretación subjetiva de las reglas.
- Evita el pago de siniestros que no cumplen con las condiciones del producto o sus exclusiones de un modo automático.
- Aporta un nivel de riesgo de fraude a aquellos siniestros que cumplen con unas características que han sido determinadas en base a la experiencia de la compañía o a la experiencia global del sector.
Las matrices de fraude son un elemento altamente eficaz, de hecho la mayor parte de las compañías dispone de mecanismos de automatización de las mismas. Sin embargo, el volumen de información que disponen las compañías está creciendo exponencialmente y por lo tanto deberíamos ser capaces de responder a la siguiente pregunta: ¿Existen otros datos distintos a los tratados en la matriz que pueden determinar el riesgo de un siniestro? Para poder responder a esta pregunta, necesitamos entrar en el siguiente paso del roadmap:
Machine Learning
Si bien las técnicas de machine learning existen de manera previa a la irrupción del BigData, es cierto que esta nueva tendencia permite que estas técnicas sean más eficaces gracias a la capacidad que disponemos para usar la totalidad de los datos para el entrenamiento de los modelos en lugar de muestreos más pequeños.
Teniendo en cuenta esta premisa, es fácil imaginar oportunidades de mejora en la automatización de la matriz de fraude si además de contar con la información proveniente de los sistemas de tramitación, pudiéramos mezclar esa información con la información que proviene de los centros de atención al usuario, correos electrónicos, la historia del cliente en la compañía y otros elementos.
Disponer de la capacidad de mezclar toda esta información aporta unas ventajas claras a la hora de determinar el riesgo de fraude de un determinado siniestro, sin embargo, hay que tener en cuenta multitud de aspectos esenciales para tener éxito en este tipo de aproximaciones:
- ¿Dispongo de la suficiente calidad en la información de mis sistemas?
- ¿Puedo mejorar dicha calidad de un modo automatizado?
- ¿Cómo puedo acceder a la información de todos los sistemas sin alterar su rutina de funcionamiento?
- ¿Cómo seleccionamos las variables más relevantes?
- ¿Cómo se aborda un proyecto de Machine Learning?
- ¿Cómo reduzco el número de falsos positivos?
Aunque intentaré responder a estas preguntas en posteriores artículos, lo que podemos determinar es que la aplicación de las técnicas de Machine Learning aportan de nuevo una serie de ventajas adicionales:
- Aumenta el rango de búsqueda de los siniestros con riesgo de fraude: La selección de nuevas variables puede determinar nuevos condicionantes hasta ahora desconocidos.
- Automatiza la identificación del riesgo a partir de la aplicación de estos modelos.
- Aporta un nuevo indicador de fraude en base a la predicción del riesgo a través de dichos modelos.
- Permite la no repetición de fraude que hayamos detectado en el pasado.
- Puede reducir el número de falsos positivos de las matrices de fraude.
Esta serie de ventajas pueden aportar una gran diferencia con respecto a la automatización de la matriz de fraude y suponen un gran retorno de inversión para aquellas compañías aseguradoras que invierten en el desarrollo de estos sistemas de detección.
Hasta este momento del “Roadmap de la detección” hemos conseguido minimizar el riesgo de reaparición de fraudes para los que tenemos indicios en el histórico de la compañía, sin embargo, ¿Podemos acercarnos un paso adicional en la detección del fraude que nunca hemos detectado en la compañía o que no tenemos consciencia de él? Las siguientes etapas nos permiten acercarnos a la resolución de esta pregunta.
Enriquecimiento de la información
Uno de los aspectos fundamentales para encontrar nuevos indicios de riesgo de fraude es disponer de otros elementos de información distintos a los que disponemos en nuestras organizaciones que puedan enriquecer la información que disponemos de nuestros clientes o del propio siniestro, para ello existen varias catalogaciones de las fuentes de información:
Redes Sociales e Internet: La sociedad ha cambiado de manera radical en los últimos años hacia la digitalización. El uso de redes sociales y blogs, entre otros es una constante en casi todos los rangos de edad poblacionales, lo que supone una gran oportunidad para las compañías si son capaces de recoger parte de esa información para enriquecer sus propios datos.
Fuentes públicas: En los últimos años se han desarrollado multitud de fuentes de libre disposición y que permiten enriquecer la información de nuestra compañía con múltiples indicadores como pueden ser valores socio económicos, valores meteorológicos, geopolíticos, etcétera. Estas fuentes de libre disposición vienen determinadas por las corrientes Open Data que se han ido desarrollando en los últimos años por los gobiernos de todo el mundo; de hecho, España es líder europeo en la puesta a disposición de los ciudadanos de multitud de fuentes de información para el desarrollo de diferentes modelos de negocio.
Fuentes privadas: Existen multitud de recursos que pueden adquirirse a través de diferentes asociaciones o empresas para enriquecer la información de nuestros clientes con un posible riesgo crediticio, patrón de comportamiento, etc. Estas fuentes de información permiten a las compañías enriquecer su información a través de acuerdos interempresa.
Si bien la disposición de estas fuentes de información para enriquecer nuestros datos puede ser un elemento diferencial en la detección de fraude, disponer de esta información no está exento de múltiples cuestiones a considerar:
- ¿Es viable disponer de esta información sin vulnerar la LOPD?
- ¿Cuál es la fiabilidad de cada una de las fuentes de información?
- ¿Qué trabajo es necesario para normalizar esta información externa e integrarla en los procesos de tramitación de mi compañía?
- ¿Qué beneficio real me aporta la incorporación de esta fuente?
Analítica de grafos
Uno de los enfoques más creativos a la hora de luchar contra el fraude o determinar el riesgo de un determinado cliente u operación, es conseguir analizar la información desde múltiples perspectivas. En este sentido, la Analítica de Grafos nos permite enfocar la detección de fraude desde un punto de vista completamente distinto al habitual, el enfoque de las relaciones.
Como hemos visto en los anteriores puntos, la mayor parte de las técnicas utilizadas consiste en analizar los datos desde el punto de vista del valor de dichos datos, sin embargo, la Analítica de Grafos nos permite modelar la información desde el punto de vista de cómo se interrelaciona la información. Este nuevo enfoque nos permite identificar nuevos indicios de fraude basándonos en cómo nuestros clientes, nuestros siniestros, nuestros datos, se interrelacionan entre sí.
La Analítica de Grafos o SNA (Social Network Analysis) es una técnica que nos permite modelar cualquier realidad en una red formada por nodos y relaciones como podemos ver en la siguiente figura:
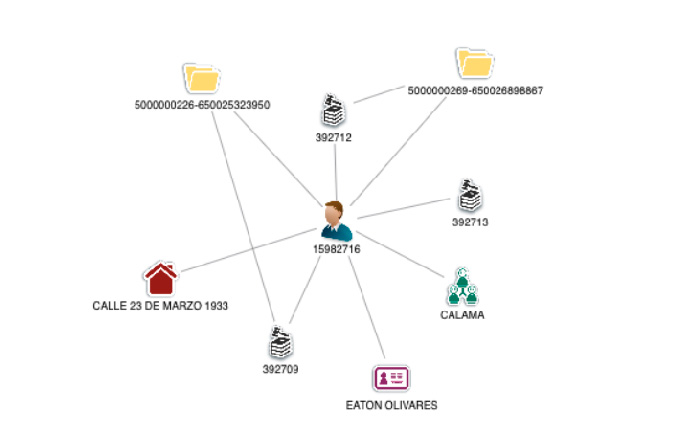
Esta aproximación nos permite acelerar los tiempos de investigación de cada caso, basándonos en que los tramitadores o analistas no tienen que imaginarse un mapa mental del siniestro sino que dichas técnicas nos aportan un enfoque completamente visual de la información.
De otro modo, la Analítica de Grafos aplicada a los datos de una compañía aseguradora nos permite conocer el comportamiento de nuestros clientes en cada uno de los siniestros de la compañía y así identificar nuevos indicios como elementos en común entre diferentes siniestros, aparición de redes organizadas de fraude, detección de secuencias temporales o patrones geográficos. Es decir, dado que el fraude lo cometen personas, utilicemos un modelado de información que nos permita “ver” como se interrelacionan dichas personas.
Pero la Analítica de Grafos no es sólo un modo de visualización o modelado, sino que nos permite la aplicación de diferentes técnicas y algoritmos matemáticos que nos
permiten inferir patrones de comportamiento en el conjunto de nuestros clientes o anomalías que se encuentran en nuestros datos de un modo automatizado.
En mi opinión, la detección de fraude o la determinación del riesgo de un determinado perfil es una tarea realmente compleja y no existen los sistemas infalibles. Sin embargo, la utilización de la Analítica de Grafos junto con el Machine Learning y el enriquecimiento de la información aporta un elemento diferenciador en la lucha contra el fraude y puede generar importantes beneficios para una compañía que decida emprender dicho Roadmap.











