

Cada vez es más habitual el uso de algoritmos de aprendizaje que permiten dotar a los programas de la inteligencia suficiente como para predecir, recomendar o clasificar elementos. Algunos ejemplos de aplicaciones que usan este tipo de sistemas de recomendación son Netflix o Spotify, que recomiendan películas o canciones que podrían interesar a los usuarios en función de sus gustos.
Spark MLlib
Ya os he hablado antes de Apache Spark en mi artículo Apache Spark: Introducción a Spark Sql, pero hoy quiero profundizar más en su librería MLlib pensada para implementar y entrenar modelos de Machine Learning de forma sencilla.
En general, los algoritmos de Machine Learning se pueden clasificar en dos tipos:
- Supervisados: estos algoritmos se entrenan con un conjunto de datos cuyo resultado ya es conocido. Es decir, el modelo se entrena con datos de los que ya se conoce la entrada y la salida.
- No supervisados: el modelo se entrena con datos de los que todavía no se conoce el resultado. Es decir, se conoce la entrada pero no la salida de los datos.
Spark MLlib aporta algoritmos tanto de aprendizaje supervisado como no supervisado que ofrecen soluciones a las tres técnicas más utilizadas en el mundo del Machine Learning:
- Clasificación y regresión: Algoritmos supervisados que clasifican o predicen valores: Multilayer perceptron classifier, Decision trees, Random forest.
- Clusterización: Algoritmos no supervisados que agrupan datos en diferentes clusters en función de la semejanza entre ellos: K-means, LDA y GMM
- Filtrado colaborativo: Técnicas de recomendación basado en datos de preferencias de los usuarios: ALS
Ejemplo de clusterización
No pretendo profundizar en el funcionamiento de cada uno de los algoritmos que nos aporta Spark. En su lugar prefiero presentaros un ejemplo de K-means para mostraros lo sencillo que puede ser entrenar un modelo con Spark. Para la implementación me he apoyado en Apache Zeppelin, que permite la exploración de los datos de una forma más sencilla y proporciona una interfaz visual con la que mostrar gráficas.
Como datos de entrada utilizados para el entrenamiento del modelo, se ha utilizado un fichero CSV que contiene información sobre contaminación acústica recogida en la ciudad de Madrid durante los años 2016 y 2017. Esta es la información contenida en el conjunto de datos, donde cada fila del fichero CSV contiene:
| Dato | Contenido del dato |
|---|---|
| Fecha | Fecha de la medida |
| Ld | Nivel sonoro medio a largo plazo ponderado A, determinado a lo largo de todos los períodos día (de 7 a 19 horas) del mes. |
| Le | Nivel sonoro medio a largo plazo ponderado A, determinado a lo largo de todos los períodos tarde (de 19 a 23 horas) del mes. |
| Ln | Nivel sonoro medio a largo plazo ponderado A, definido determinado a lo largo de todos los períodos noche (de 23 a 7 horas) del mes. |
| LAeq24 | Nivel sonoro medio a largo plazo ponderado A, determinado a lo largo de todos los períodos diarios (24 horas) del mes. |
En primer lugar se han leído los datos del fichero, se han limpiado y se ha transformado a DataFrame:
import org.apache.spark.ml.clustering.KMeans
import org.apache.spark.ml.feature.VectorAssembler
case class AcousticData(date: String, ld: Double, le: Double, ln: Double, lAeq: Double)
// Create DataFrame from CSV file
val acousticDF = sc.textFile("/home/dgrana/BigData/Acoustic_2016-17.csv")
.filter(x => !(x.contains("Fecha") || x.contains("N/D") || x.split(";").length<5))
.map({
line =>
val row = line.split(";")
AcousticData(
row(0),
row(1).replace(",",".").toDouble,
row(2).replace(",",".").toDouble,
row(3).replace(",",".").toDouble,
row(4).replace(",",".").toDouble
)
}).toDF()
acousticDF.createOrReplaceTempView("ACOUSTIC_DATA")Una vez obtenido el DataFrame, se entrena el modelo con un algoritmo K-means, indicando que nos clusterice los datos en cinco clústers diferentes. Además, creamos una tabla con los resultados de la predicción:
// Asembler to create a features vector
val assemblerKmeans = new VectorAssembler().setInputCols(Array("ld","le","ln","lAeq"))
.setOutputCol("features")
// Set the features column
val vd = assemblerKmeans.transform(acousticDF)
// Trains a k-means model.
val kmeans = new KMeans().setK(5).setSeed(1L)
val model = kmeans.fit(vd)
// Evaluate clustering by computing Within Set Sum of Squared Errors.
val WSSSE = model.computeCost(vd)
println(s"Within Set Sum of Squared Errors = $WSSSE")
val predictions = model.transform(vd)
predictions.createOrReplaceTempView("ACOUSTIC_DATA_KMEANS")Por último, se comprueban los resultados obtenidos:
SELECT prediction, count(*) from ACOUSTIC_DATA_KMEANS group by 1El objetivo de este ejemplo es clusterizar los niveles acústicos recogidos en función de su parecido.
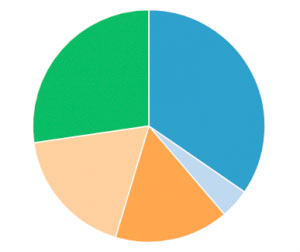
Como se ve en la imagen, los datos se han clusterizado en base a su similitud. El agrupamiento resultante es de forma irregular, ya que hay un clúster considerablemente más pequeño que el resto. Si se considera lo suficientemente pequeño, los valores que han sido clasificados en dicho clúster se pueden considerar outliers o valores atípicos que pueden referenciar a datos de niveles acústicos anormales. Pero para tomar este tipo de conclusiones es necesario profundizar más en el análisis de los datos.
Análisis de datos con Spark MLlib
Spark MLlib nos proporciona una forma sencilla y escalable de entrenar y aplicar distintos modelos y algoritmos de Machine Learning sobre nuestros datos, extrayendo todo el valor de ellos, sin necesidad de complejas herramientas de análisis, ni de grandes desarrollos a medida.












