
Initiatives such as the ODINE (Open Data Incubator for Europe) accelerator, which aims to support SMEs and startups in developing businesses based on open data, are a clear example of the current commitment to Open Data. But what exactly is Open Data? Let's start by analyzing the two words that make up this concept.
Open, a very popular term several years ago, can be found in Open Source, Open Knowledge, MOOC (Massive Open Online Course) and many other disciplines. In all of them, the word Open offers the possibility to any person to access "something" to use, modify and share it with practically no restrictions, the only thing that is usually asked is to preserve its authorship and maintain its open quality.
Data comes from the Latin "Datum", which means "that which is given". It is a symbolic representation that can be qualitative or quantitative. Data by itself has no value. It is through its proper processing within a context that it can be converted into useful information. In computing, data are fundamental and highly valued, as they are the raw material for the development of any algorithm. Open Data, are those data that can be used, reused and redistributed freely by any person without any restriction or copyright facilitating as far as possible the interoperability with other data sets.
There are already many of us who consider data the black gold of our time. Giants like Google or Facebook, the great mass collectors of any kind of data, have shown, through Big Data tools and processing techniques, how they manage to transform their huge amounts of data into very valuable information and huge benefits. And that's because their free services were never free.
According to the IDC consulting firm, 90% of the data worldwide has been created in the last two years alone. By 2020, we could surpass the dizzying figure of 40 ZB (zettabytes) of information, which is 50 times greater than in 2010. This is about 5,247 GB per person.
What if any person or company could have access to this enormous amount of data generated by our society? Well, this is exactly what the philosophy of the Open Data movement is all about.
What data should be opened?
More and more voices are calling for the adoption of open data policies by public administrations in order to promote transparency and participation in economic development.
The data generated and obtained by state institutions and private organizations financed with public money should not be considered the exclusive property of these, but should be shared with citizens and companies, so that they can be used for consultation, to analyze them or to cross them with other data, making it possible to generate new services, products and businesses within the reach of all.
Data opened by government entities is known as Open Government Data. According to the latest annual report of the European Public Data Portal, Spain is the leading European country in its development due to the number and quality of open sources. In datos.gob.es we can find the different datasets published by the Spanish government.
In the private sector the situation is different. Impediments such as competition, data privacy or legislation complicate the publication of open data by companies, although examples of open corporate data are beginning to be found, with the aim of facilitating the creation of new solutions based on their data.
The opening of data provided by public or private organizations in any format is welcome. Currently, open data can be found in a multitude of formats, unstructured, semi-structured or structured. Some of the most common are PDF, TXT, CSV, XLS, XML, JSON, RSS, KML, WMS, WFS, GPX, RDF...
Measuring data quality
Tim Berners-Lee, father of the web and current director of the W3C (World Wide Web Consortium), recently awarded the ACM Turing Award 2016, the "Premio Novel de la Informática", proposed a five-star rating to measure the quality of open data. The scheme should be understood as a cumulative system, where the higher levels include the lower ones.
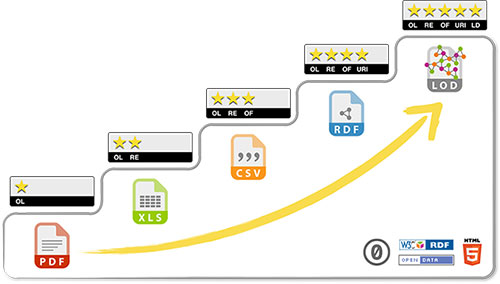
- On the first level the data is available on the Internet in any format, but always with an open license. This is the easiest way to publish data, however, data extraction by a machine is complicated and error-prone.
- A further star means that the data must also be published in a structured form, thus facilitating processing for machines. Automatic extraction can still be a problem if the right proprietary software is not available.
- At this level, structured data should use non-proprietary formats, for example, CSV instead of Excel. The data can be exploited without any proprietary software.
- Four stars means that W3C standards such as RDF (Resource Description Framework) and SPARQL (Protocol and RDF Query Language) are used and a URI (Uniform Resource Identifier) is used to identify the data, which can then be shared and integrated on the Web.
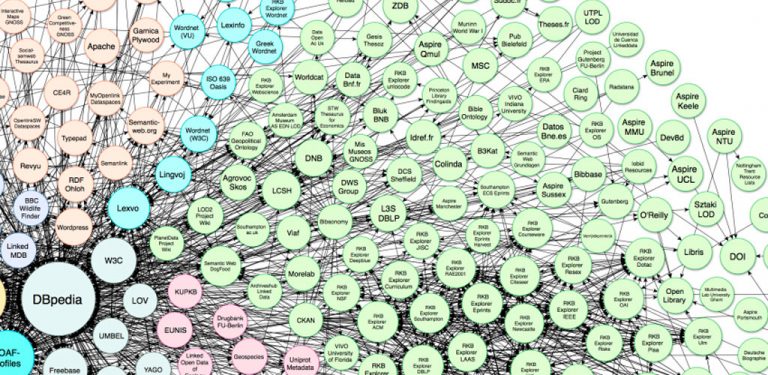
- In addition to all the above, it means that the data is linked to other data, creating a data network that creates a context. They allow in the information processing itself to include other data related by discovery. In this last level, where open data and linked data are joined, is where the term LOD (Linked Open Data) appears. In lod-cloud.net you can consult datasets that comply with this level, as well as the relationship between them.
Where are we now?
How wonderful would be a five star Network, open data linked, allowing people and machines to explore the data network in a simple way and getting a little closer to the reality of a Semantic Web thanks to better defined data and the relationship between them, giving more meaning to the current Web.
In the meantime, efforts should be made to reach at least the third level. At the current stage of adolescence in which Open Data is found, it is beginning to be considered that below this level the minimums to be considered acceptable are not met. Perhaps by the time they reach adulthood they will have to comply with at least the fourth level and in maturity they will have to be linked to other data, so that they are referenced in the same way as we do now with the links on the web pages.
Publishing open data
As publishers, you will need to select and prepare the data to be published, as well as define the formats in which you want to publish, trying as much as possible to make it interoperable with data from other sources.
In the case of the use of personal data, the data must be anonymized, eliminating any trace of sensitive information of persons or organizations.
To facilitate the opening of data, there are platforms that help to publish data on the web easily and quickly, without having to spend a great deal of money and resources. CKAN is the open data software solution most in demand today. It has tools to publish, manage, share, find and use data, including storage. Portals such as data.gov.uk or publicdata.eu are developed under this open source platform.
A business opportunity
Open data publishing will continue to grow unstoppably in the future. Companies have an opportunity to generate new business based on open data. For example, data published by the National Geographic Institute is used by CartoDB or Google Maps for their businesses.
Open Data today generates 13,000 jobs and a turnover of about 1.7 billion in SpainVíctor Calvo-Sotelo (Secretary of State for Telecommunications and the Information Society)








