

En los últimos artículos hemos hablado sobre analizar documentos sin leerlos, así como de los casos de uso que le podemos dar a una herramienta de este tipo. Una de las aplicaciones que se comentó en ese primer artículo fue el de clasificación del estado del arte pero, ¿qué significa esto exactamente? A continuación trataremos de explicarlo mediante un ejemplo:
Supongamos un bibliotecario cuya biblioteca acaba de estrenar una sección de libros de química. El bibliotecario, carece de la formación necesaria para conocer las diferentes sub-temáticas presentes en esta disciplina, sin embargo, se ve en el deber de dotar a las estanterías de cierta estructura en lugar de limitarse a colocar los libros aleatoriamente. Este es precisamente el problema que trata la clasificación del estado del arte. Es decir, sin saber nada de las diferentes temáticas presentes en los documentos que tenemos entre manos podemos ser capaces de realizar una clasificación de los mismos. Dicha clasificación se realiza en base a la similitud de los textos.

Esta es la idea básica del problema, pero hay muchos asuntos importantes que merece la pena comentar, vamos a ello.
¿En cuántos grupos clasificamos nuestros documentos?
Siguiendo con el ejemplo que expusimos en el apartado anterior podemos encontrarnos con dos casuísticas.
Número de grupos predefinido
Figuremos que el bibliotecario solo dispone de una estantería para clasificar sus libros de química. Más aún, la estantería consta exactamente de cinco estantes. El bibliotecario, pulcro y meticuloso, decide seguir el formato del resto de la biblioteca: una estantería por temática, a su vez dividida en otras cinco subcategorías. En este caso, está claro que la clasificación de los textos debe ceñirse exclusivamente a estas cinco clases. De esta manera, y en la línea de lo que comentábamos anteriormente, debemos forzar a nuestro algoritmo a encontrar cinco grupos en los que clasificar los textos, de forma que los documentos pertenecientes a un mismo grupo sean los más parecidos entre sí. Llegados a este punto podemos encontrarnos con tres posibilidades:
- Todos los textos son muy parecidos entre sí por lo que cinco grupos son demasiadas subdivisiones.
- Los textos son tan diferentes que hacen falta más de cinco categorías. De otra manera nos encontraríamos en una misma categoría con textos de muy diversa índole.
- Cinco es el número óptimo de grupos en función a la varianza de los documentos.
Sin restricciones sobre el número de grupos
La segunda de las opciones es que el bibliotecario tenga varias estanterías disponibles, con lo cual no tiene ninguna restricción inicial para el número de grupos en los que clasificar los libros. Esta vez, lo más conveniente antes de elegir el número de grupos es realizar una optimización de dicho parámetro. Para este propósito tenemos varias opciones:
- Prueba y error, junto con matemáticas y capacidad de cómputo, hasta que quedemos contentos con los grupos resultantes. En este caso el bibliotecario a media que tenga tiempo (lo que en la práctica se traduciría como capacidad de cómputo) deberá ir leyendo los libros. Así tendrá una visión de que tan bien formados están los grupos (lo que en la práctica se traduce en asignar un métrica de coherencia). De esta forma, después de probar varias agrupaciones, podría seleccionar la mejor.
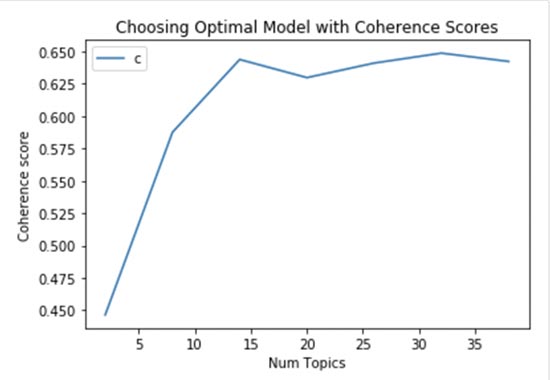
- Conocimiento de negocio. Quizá nuestro bibliotecario no tenga la más remota idea sobre química, pero resulta ser un genio tanto en física como en matemáticas. Su experiencia le dice que en este tipo de ciencias suele haber siempre más de 8 subcategorías, pero nunca más de 14. De esta forma ya tendría un rango por el que empezar a tantear. O por el contrario no tiene idea de ciencias en general, pero su colega de una librería cercana ya ha pasado por el escollo de ordenar la sección de química y le recomienda un determinado número de subcategorías.
¿Un libro puede pertenecer a más de un grupo?
La respuesta es que sí. En realidad nuestro algoritmo de clasificación del estado del arte no tendrá como resultado el grupo al que pertenece el texto, sino que arroja la probabilidad de pertenencia a cada grupo. A partir de ahí lo más común es asociar al texto el grupo al que más probabilidad tiene de pertenecer, pero podrían darse circunstancias como las siguientes:
- La probabilidad de pertenecer a varios grupos es muy parecida. Esto ocurrirá sobre todo cuando tengamos un número pequeño de grupos en los que clasificar. En este caso el bibliotecario podría poner al libro ambas etiquetas o bien decantarse por una de ellas a sabiendas de que cualquier clasificación es igual de acertada (o desacertada).
- Ninguna de las probabilidades es lo suficientemente alta como para decidir clasificar el libro en un grupo con cierta confianza. En este caso, si ocurriese con muchos de los libros el bibliotecario podría plantearse establecer algún grupo más, por ejemplo con la etiqueta “otros” o “misceláneo”.
¿Cómo sabemos cuál es la temática de cada grupo?
Una vez tengamos los textos clasificados en el número de grupos convenido, el bibliotecario tendrá que poner una etiqueta en cada estante indicando la temática. Una estrategia inteligente para una persona podría ser simplemente leer las sinopsis y los títulos de los libros de cada grupo. En este sentido sería lógico encontrar palabras clave y coincidencias que puedan ayudar a establecer la temática. Algo similar ocurre con nuestro algoritmo, este se basa en encontrar las palabras más características de cada grupo así como los textos más representativos de los mismos. De esta forma, de un solo vistazo podremos poner una etiqueta a posteriori de la creación de los grupos.
Y a nivel técnico… ¿qué estamos usando?
En el último artículo de nuestro blog que trataba esta temática, Las 5 W del análisis de documentos, se habló del término NLP. Si bien es cierto que el procesamiento del lenguaje natural es el campo de trabajo clave para la clasificación según el estado del arte, hoy iremos un pasito más allá e introduciremos el algoritmo en el que nos hemos centrado para desarrollar esta aplicación.
Latent Dirichlet Allocation (LDA):
Se trata de un algoritmo de aprendizaje no supervisado que permite representar los documentos en diferentes tópicos. El algoritmo tiene como resultado una probabilidad de pertenencia a cada uno de los grupos establecidos.
La idea principal de este algoritmo es que cada documento va a ir asignado a un grupo, y a su vez cada grupo va a ir asignado a una serie de palabras que son las más relevantes o explicativas para dicho grupo.
Lo veremos más claro con las siguientes imágenes. En primer lugar simplemente asociamos cada palabra de nuestro corpus (el conjunto de todas las palabras que aparecen en los textos unas vez los hemos procesado) a un documento lo cual, a priori, no aporta mucha información en nuestra clasificación del estado del arte.
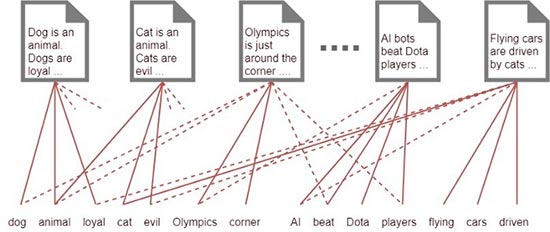
A poco que tengamos un corpus medianamente extenso no seremos capaces de procesar la información anterior. Por el contrario si asociamos cada palabra a una clase, grupo o tema encontramos una forma sencilla de clasificar cada documento y las relaciones quedan mucho más claras que en la primera imagen.
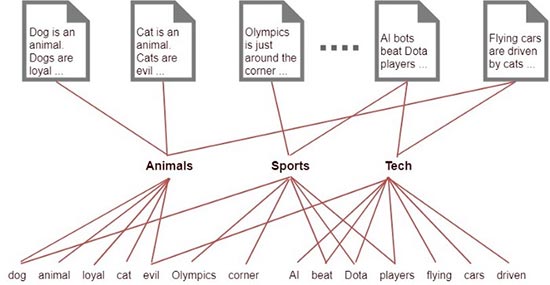
Las matemáticas detrás de este algoritmo son densas, pero eso lo dejamos como ejercicio para aquellos lectores curiosos.
Hasta aquí la aplicación de hoy, sin duda con ella el bibliotecario habría tenido las cosas más fáciles y podría haberse ahorrado leerse una estantería de libros de química si no fueran de su interés. Aún quedan otros casos de uso como el evaluador de facturas o el observatorio de publicaciones tecnológicas que comentaremos en los siguientes artículos. ¡No te lo pierdas!











