

Primeras reacciones a la presencia de IOT en el café.
Las reacciones al anuncio de la presencia IOT en el café no se han hecho esperar, por oleadas de curiosos.
Se ha inspeccionado la máquina de café en busca de enchufes inteligentes. Incluso algún empleado ha dedicado la mañana a la revisión de todos los dispositivos de la empresa. Pero cualquier rastro de vandalismo ha desaparecido, y se sigue sin saber nada sobre los autores de los hechos (aunque no se han desmentido los rumores sobre un grupo organizado de aficionados a la leche condensada)Mientras se sigue a la espera de un comunicado oficial que calme las inquietudes de la gente, los grupos más extremos están ganando influencia en la opinión pública. En la tarde de ayer, se decidió iniciar una campaña de boicot contra el café.
Así pues, esta mañana ha sido fácil ver a compañeros que han traído termos llenos de mate o que se han pasado al consumo de té mascado. Por nuestra parte, no nos hemos quedado parados, y hemos enviado a Future Space a un grupo especializado en periodismo de investigación, y han tenido acceso a información sobre NiFi, la principal herramienta utilizada en la contaminación del café.
¿Qué es NiFi?
Apache NiFi es una herramienta informática de la Fundación Apache, que permite automatizar y manejar flujos de datos entre distintos sistemas (bases de datos, colas Kafka, sistemas de ficheros, clusters de Hadoop, servicios web…), actuando sobre los propios datos en tiempo real (recolección, cambio de formato, análisis, filtrado, enriquecimiento, transformación…), y cobrando pleno sentido en un entorno de grandes volúmenes de datos (big data), si bien puede ser empleada perfectamente fuera de este contexto.
Componentes de un flujo de NiFi
Para entender cómo funciona NiFi, es conveniente definir en primer lugar los principales elementos que conforman los flujos de datos desarrollados con esta herramienta:
- Ficheros de flujo:
Los datos que se manejan en un flujo de NiFi no se tratan ni en su formato original ni en bruto, si no que se encapsulan en los llamados ficheros de flujo (flowfiles, abreviados comúnmente como FF), que permiten añadir una capa de metadatos muy útil para trabajar con la información a lo largo del flujo.
Estos metadatos se denominan atributos, y pueden almacenar cuánta información se quiera. Por ejemplo, si nuestros datos fueran registros de una tabla de una base de datos relacional, y quisiéramos almacenarlos en un fichero, podríamos tener atributos con información sobre el nombre de la tabla de la que proceden los registros, los nombre de las columnas, la ruta del fichero en el que debe guardarse el registro, etc. - Procesadores:
Los procesadores son contenedores de código que realizan operaciones sobre los FF. Así pues, para implementar un flujo de NiFi, se debe crear una secuencia de procesadores que reproduzcan la secuencia de acciones que se quieren llevar a cabo sobre los datos.
Si bien es posible diseñar los procesadores personalizados que se quiera, por defecto, NiFi nos ofrece un amplio catálogo (casi 300 procreadores en NiFi 1.8.0) que cubre ampliamente las operaciones más frecuentes que se van a necesitar en un flujo de datos: añadir atributos al FF, capturar cambios en una base de datos, cambiar de formato el contenido del FF (Avro, json, csv…), extraer el contenido textual de un fichero, extraer el valor de un campo de un fichero json a partir de su ruta, extraer cabeceras de un email, consultar a ElasticSearch, geolocalizar una IP, obtener un fichero de una cola Kafka, escribir en un log, unir el contenido de varios FFs, realizar una petición HTTP, transformar un fichero XML, validar un fichero csv, enviar mensajes a un web socket, etc. - Conexiones:
Las conexiones son enlaces orientados o dirigidos (con un origen y un destino que determinan un sentido), y permiten establecer el flujo de datos en sí, es decir, permiten determinar cómo viaja el FF a lo largo de los procesadores. Para ello, una conexión debe iniciarse en un puerto de salida de un procesador, y terminar en un puerto de entrada de otro procesador (o del mismo si se trata de una operación en bucle, por ejemplo, en el caso de un procesador que intente reiteradamente subir un fichero a un servidor web).
Las conexiones vienen caracterizadas y nombradas por el tipo de puerto de salida del procesador en el que nacen, lo que hace que sean potencialmente infinitos los tipos de conexión que podemos encontrar. Sin embargo, en la mayoría de los casos nos enfrentaremos a conexiones de tipo succes, que recogen el FF que devuelve un procesador cuando ha terminado satisfactoriamente su tarea, o de tipo failure, que conducen el FF en los casos en los que la tarea ha fallado. Además de todo lo anterior, cabe mencionar que existe la posibilidad de configurar algunos aspectos de la conexión, como el número de FF que pueden conducirse de forma simultánea por ella, el criterio con el que se establece la prioridad de salida de los FF que haya en la conexión, o el tiempo que éstos pueden permanecer a la espera de ser recogidos por el procesador de destino. - Controladores de servicios:
Este es el tipo de componentes al que menos atención se presta cuando se empieza a utilizar NiFi, sin embargo, son un elemento clave en el funcionamiento de esta herramienta. Se trata simplemente de servicios compartidos que pueden ser empleados por elementos de NiFi como los procesadores, para la realización de sus tareas. Entre ellos, encontramos lectores y escritores de ficheros en distintos formatos, conexiones a bases de datos, servicios de caché distribuida, etc.
Un ejemplo de flujo (que no es lo mismo que un flujo de ejemplo)
Para visualizar mejor cómo son los componentes de un flujo de NiFi, veamos un ejemplo sencillo, compuesto por dos procesadores y un conector:
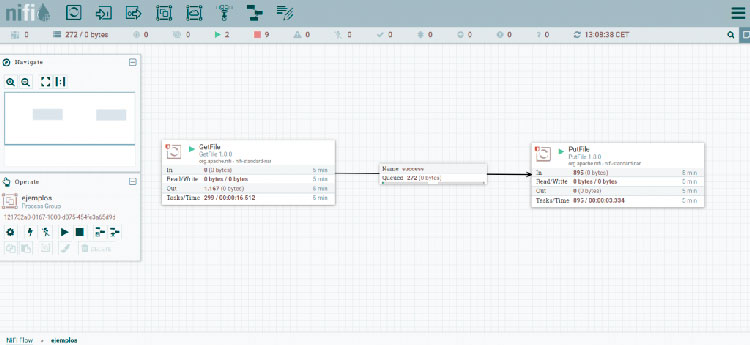
NOTA: Para poder visualizar los FFs encolados, se ha ralentizado la ejecución de los procesadores. De no haberse efectuado esta modificación, el proceso de cambio de directorio de los archivos, tendría una duración del orden de los milisegundos, a pesar de ejecutarse en mi equipo de trabajo local (el cuál está muy lejos de parecerse a un entorno de producción habiatual o a un entorno Big Data).
El primer procesador, que es de tipo GetFile, recoge ficheros de un directorio local. Si nos fijamos en la información que se muestra en su caja, veremos que han salido 1167 FFs de él en los últimos 5 minutos. De éstos FFs, 272 se encuentran aún encolados en el conector (de tipo succes), a la espera de ser recogidos por el procesador de tipo PutFile. Este procesador, simplemente pone los ficheros en un directorio local, habiendo procesado, tal y como se puede ver en la información de su caja, 895 FFs en los últimos 5 minutos.
Con estos pocos elementos, tendríamos montado un flujo de NiFi sencillo, que mueve ficheros, en tiempo real, de un directorio a otro dentro del sistema de ficheros local.
Trabajar con NiFi
Habiendo expuesto esta introducción de los elementos principales que componen un flujo de NiFi, resulta más fácil abordar en qué consiste esta herramienta: NiFi es una aplicación diseñada bajo el paradigma de la programación basada en flujos, un caso, a su vez, del paradigma de programación de flujos de datos que conlleva un desarrollo basado en componentes.
Toda esta parafernalia, viene a decir que a nivel algorítmico, el flujo de datos se puede diseñara alto nivel, estableciendo una sucesión de acciones (realizadas por los procesadores) sobre los datos (contenidos en el FF), sin necesidad de preocuparse de la lógica interna de cada una de estas operaciones. Con ello se crean redes de procesos de caja negra, que funcionan como componentes que intercambian datos haciendo uso de las conexiones que entre ellos se hayan predefinido. Además, nos encontramos ante un programa con interfaz gráfica, en el que se opera, principalmente, mediante drag and drop (para añadir procesadores o para establecer las conexiones entre ellos), añadiendo un aspecto más que permite alejarnos de los grandes desarrollos de software llenos de líneas de código. Pero, quizá lo más interesante de NiFi sea el cambio de estrategia que plantea de cara a los tiempos de procesamiento y a los volúmenes de datos que maneja.
La propia idea de flujo nos lleva a pensar en una corriente continua de datos de volumen controlado. No nos encontramos ante una herramienta pensada para realizar tareas en batch que se lanzan una vez al día y manejan de golpe todos los datos acumulados. NiFi, es más bien una herramienta de streaming, en la que se trabaja en el mismo momento en el que ocurren las cosas, tratando los datos registro por registro. Y esta es la puerta por la que NiFi entra en el mundo del big data, ya que de esta forma, es posible manejar grandes volúmenes de datos sin invertir en enormes recursos de hardware, y se minimizan las repercusiones de un error, ya que un fallo en el procesamiento de un FF que almacene un registro no se propaga al resto de los datos.
NiFi en el proyecto Café con IOT
El enchufe inteligente que monitoriza el consumo de electricidad de la máquina de café de FutureSpace, no tiene memoria, no almacena los datos, así pues, toda su potencial información se termina perdiendo.
Para poder acceder a los datos que genera, es necesario efectuar consultas HTTP a su API, con las cuales se puede conocer el valor de la corriente en el instante de la consulta. Por lo tanto, si se busca monitorizar el consumo eléctrico de la máquina de café, se hace necesario efectuar estas consultas de forma periódica, en intervalos relativamente cortos (por ejemplo, cada 2 segundos). Además, no basta con recoger este dato, sino que se hace necesario almacenarlo en un sistema que le de persistencia.
No sería descabellado plantearse guardar estos datos en algún tipo de fichero (por ejemplo, en uno de formato csv), de tal forma que la información pueda ser manejada y explotada posteriormente. Bueno, pues NiFi está pensado para hacer, precisamente, operaciones como las anteriormente descritas, por lo que, para el proyecto Café con IOT se desarrolló el siguiente flujo:
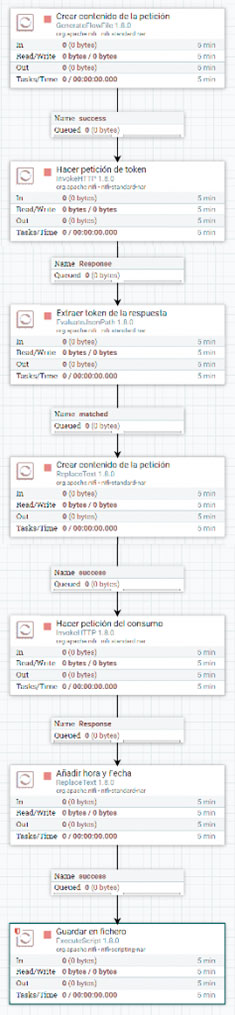
- Crear contenido de la petición:
Este procesador genera un nuevo FF cada 2 segundos. En el contenido del mismo se incluye el cuerpo (en formato json) de la petición que se debe hacer al API del enchufe para obtener el token de autenticación, con el cual se podrán hacer otras peticiones. - Hacer petición de token:
Este procesador llama al API del enchufe, para efectuar una petición de tipo POST cuyo cuerpo se encuentra en el contenido del FF anteriormente generado. El resultado de esta petición, que incluye el token de autenticación para pedir datos al enchufe, pasa a conformar el nuevo contenido del FF. - Extraer token de respuesta:
Por cuestiones de funcionamiento del flujo, es necesario extraer el token que se encuentra en el contenido del FF, y ponerlo como un atributo o metadato del mismo, de tal forma que no se pierda el token aunque cambie el contenido del FF. - Crear contenido de la petición:
Una vez más, es necesario incluir en el FF el cuerpo de una petición a la API, en esta ocasión, con la intención de obtener el valor del consumo en el momento de la petición. - Hacer petición de consumo:
Se efectúa una petición de tipo POST similar a la anteriormente efectuado para obtener el token, y se obtiene en la respuesta el consumo instantáneo de electricidad, que es almacenado en el FF. - Añadir hora y fecha:
Con objeto de enriquecer el dato del consumo, se añade, al contenido del FF, la fecha y hora en la que se ha efectuado la consulta, adaptando estos datos a un formato adecuado para un registro de un fichero de tipo csv. - Guardar en fichero:
Finalmente, el contenido del FF se almacena como una nueva línea en un fichero csv que guarda el histórico de consumo eléctrico de la máquina de café que registra el enchufe.
NiFi, ¿ni fu ni fa?
En FutureSpace, se ha empleado NiFi en varios proyectos (además de en este acto vandálico), y en todos ellos nos ha hecho pasar por una montaña rusa de emociones. Ha habido momentos de pánico, de odio, de admiración, de frustración, de satisfacción… Pero la verdad, es que en el fondo, me da la impresión de que NiFi me encanta. Creo que es una herramienta estupenda para hacer lo que hace (manejo de flujos de datos en streaming), y que quizá los problemas aparezcan cuando es usada para hacer otras cosas. Lo que no tengo muy claro es si somos nosotros los que forzamos su uso, o si es el propio NiFi quien parece invitarte a sobrepasar su no-explicitamente-delimitada zona de confort. En cualquier caso, cuando un grupo de vándalos ha tenido la oportunidad de elegir sin restricciones las herramientas con las que contaminar de IOT la máquina de café de su empresa, su elección ha sido NiFi.
¿Y qué hay dentro del fichero en el que NiFi guarda los datos de consumo eléctrico? Lo veremos en las siguientes entregas de Café con IOT
*Nota al margen…Para los curiosos: ¿Qué es el Big Data?
BIG DATA En 1632, Galileo Galilei publica Dialogo sopra i due massimi sistemi del mondo (Diálogo sobre los dos principales sistemas del mundo), un libro en el que, al estilo de los diálogos griegos clásicos, expone las conversaciones que mantienen un filósofo geocentrista y otro heliocentrista (lógicamente, con la intención de defender esta última postura). Y fue esta la obra que colmó el vaso de la “paciencia”” de la Santa Inquisición, la cual condenó a Galileo a prisión perpetua, así como a abjurar de sus ideas respecto al movimiento de los cuerpos celestes. Y Galileo abjuró (a pesar del supuestamente dicho eppur si muove). Pero lo que me interesa de esta obra es que, en un determinado momento, habla de big data. [Pausa dramática para que el lector se escandalice ante la afirmación anterior]
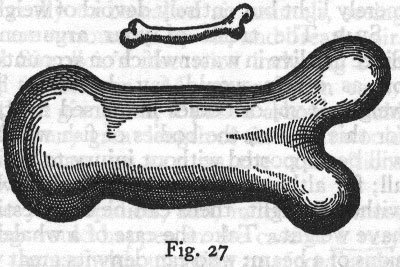
Imagen del Dialogo de Galileo De lo que habla Galileo en una parte de su obra es de los cambios de escala, en concreto, de lo que le ocurriría a un hueso, si se aumentara el tamaño del animal al que pertenece. Y lo interesante es que, llega a la conclusión de que aumentar algo no es un proceso lineal. Al aumentar el tamaño global de un animal, no basta con aumentar el tamaño del sistema que lo sostiene (los huesos), sino que hay un punto en el que es necesario modificar el sistema en sí. Y esto es big data.
Podríamos pensar que, al aumentar el volumen de los datos, lo que debemos hacer es aumentar los recursos para manejarlos (memoria, procesadores, almacenamiento en disco…). Pero ésta no ha resultado ser la solución. Lo que caracteriza a las tecnologías big data es que, para hacer con los datos las mismas cosas de siempre (almacenar, procesar, consultar, visualizar…), ofrecen soluciones distintas a las tomadas para volúmenes más pequeños. Y no son distintas por capricho, lo son por eficacia, porque lo que funciona a una escala, no funciona en otra, porque la escalabilidad no siempre es cuestión de más, si no de otro.










