

The data is the basis of our systems. The raw material from which our applications and analyses are fed. Whether it's a system upgrade, an architectural change that changes the storage medium, or a response to the need to assimilate data from other sources, the movement of data is one of the most complex and critical challenges we can face.
First of all, we can't lose data. The transfer, whether periodic or not (as would be the case with a migration, which is done only once... if nothing fails) must guarantee this fact. Also, as a general rule, the movement will require transformations and conversions of the information, for example, to adapt it to the architecture of the target system. In cases such as data migration, in-service stops are required, stopping the source system until the target system is fully operational.
In others, such as the intake of information from external sources, the focus is on the need to transform the data to fit our systems, without forgetting problems such as performance or not affecting the service of the source or the destination.
For those cases where the data transfer is periodic, or at least will be reproducible, we can count on a powerful tool, which can help us to perform this task.
Apache NiFi is a data transformation and routing stream execution engine. Simply put, it loads data from one source, passes it through a process flow for processing, and dumps it into another source.
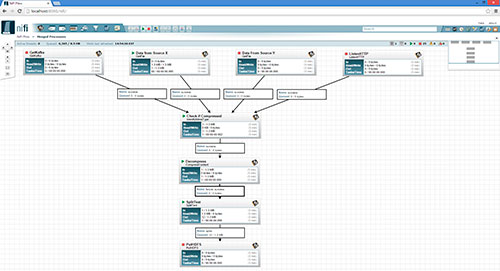
In this example we can see how a flow has been defined in which data from various sources are unified, before passing through a series of processors, to end up stored on a common medium. This flow can be branched out as much as necessary.
User Interface
The Apache NiFi web application is one of its strengths. Not only does it allow you to design and configure visually the flow through which the data will travel, but, from that same view, you can both operate on the process (start and stop) and monitor the status, seeing the possible errors that have occurred.
This flow can be modified during its execution, simply by stopping the process at one point, and making the changes. The data is queued in the previous step, until the execution is resumed.
Processors
Each of the boxes that are part of the flow, the processors, provide a specific functionality to the flow. NiFi comes pre-loaded with a long list of operations on the data, in the form of processors:
- Interaction with data sources. Uploading data from and to a wide variety of formats and technologies: HDFS, ElasticSearch, FTP, SQL databases, MongoDB, files... among many others.
- Data conversion. Information structure changes, from and to JSON, XML, Avro, CSV, etc.
- Information processing. Data joining and division operations, as well as their validation and transformation.
- Delegation of functionalities. Processors that can transfer data to other processing systems, to perform tasks on them, that are already implemented in other systems: For example, the bi-directional communication with a third party, through Kafka queues, or the transparent execution of Apache Flume processes.
For specific cases in which data processing requires something ad hoc, NiFi provides a mechanism to integrate a defined process into a simple java class, like another processor into the flow design.
Cluster execution
To ensure optimum performance, the process defined in this tree can be executed in parallel: Several machines on which NiFi is running collaborate to perform the operations defined in one of them.
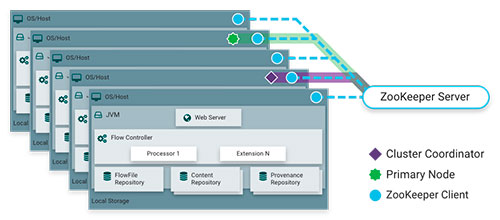
This execution is programmed within the NiFi web interface, either at time intervals, or through a crontab mask. Within the execution options, we have MiNiFi, a NiFi-derived project, which provides us with a runtime with low requirements, to execute defined flows exported from NiFi, conserving the resources of the machine where the process is executed.
One step beyond ETL
After this first contact with Apache NiFi, we can realize that because of the simplicity of its use (completely integrated in a web application), and the power of its capabilities (with complex processor flows, provided or created to measure) is a very important tool for the transfer of data between systems.








