

First reactions to the presence of IOT in coffee.
Reactions to the announcement of the IOT presence in the coffee have not been long in coming, due to waves of onlookers.
The coffee machine has been inspected for intelligent plugs. Some employees even spent the morning checking all the company's devices. But any trace of vandalism has disappeared, and nothing is known about the perpetrators (although rumours of an organised group of condensed milk fans have not been denied). Yesterday afternoon, it was decided to launch a campaign to boycott coffee.
So, this morning it was easy to see colleagues who brought thermoses full of mate or who switched to chewed tea. For our part, we have not stood still, and we have sent Future Space a group specialized in investigative journalism, and they have had access to information about NiFi, the main tool used in the contamination of coffee.
What is NiFi?
Apache NiFi is a computer tool of the Apache Foundation, which allows to automate and manage data flows between different systems (databases, Kafka queues, file systems, Hadoop clusters, web services...), acting on the data itself in real time (collection, format change, analysis, filtering, enrichment, transformation...), and making full sense in an environment of large volumes of data (big data), although it can be used perfectly out of this context.
Components of a NiFi flow
To understand how NiFi works, it is convenient to first define the main elements that make up the data flows developed with this tool:
- Flowfiles:
The data handled in a NiFi flow is neither treated in its original format nor in its raw form, but is encapsulated in so-called flowfiles( flowfiles, commonly abbreviated as FF), which allow you to add a layer of metadata very useful for working with the information along the flow.
These metadata are called attributes, and can store as much information as you want. For example, if our data were records from a table in a relational database, and we wanted to store them in a file, we could have attributes with information about the name of the table the records came from, the names of the columns, the path to the file where the record should be stored, and so on. - Processors:
Processors are code containers that perform operations on the FF. So, to implement a NiFi flow, you must create a sequence of processors that reproduce the sequence of actions that you want to carry out on the data.
Although it is possible to design the custom processors you want, by default, NiFi offers a wide catalog (almost 300 procreators in NiFi 1.8.0) that widely covers the most frequent operations that are going to be needed in a data flow: add attributes to the FF, capture changes in a database, change the format of the FF content(Avro, json, csv...), extract the textual content of a file, extract the value of a field in a json file from its path, extract headers from an email, consult ElasticSearch, geolocate an IP, obtain a file from a Kafka queue, write in a log, join the content of several FFs, make an HTTP request, transform an XML file, validate a csv file, send messages to a web socket, etc. - Connections:
Connections are oriented or directed links (with an origin and a destination that determine a direction), and allow the flow of data itself to be established, that is, they allow you to determine how the FF travels along the processors. To do this, a connection must start on an output port of one processor, and end on an input port of another processor (or the same one if it is a loop operation, for example, in the case of a processor that repeatedly tries to upload a file to a web server).
The connections are characterized and named by the type of output port of the processor on which they are born, which makes the types of connection we can find potentially infinite. However, in most cases we will face success-type connections, which pick up the FF that a processor returns when it has successfully completed its task, or failure-type connections, which conduct the FF in cases where the task has failed. In addition to all the above, it is worth mentioning that there is the possibility of configuring some aspects of the connection, such as the number of FFs that can be simultaneously carried by it, the criterion with which the output priority of the FFs in the connection is established, or the time they can remain waiting to be picked up by the destination processor. - Service controllers:
This is the type of component that is paid the least attention to when starting to use NiFi, however, they are a key element in the operation of this tool. They are simply shared services that can be used by NiFi elements such as processors to perform their tasks. Among them, we find readers and writers of files in different formats, database connections, distributed cache services, etc.
An example flow (which is not the same as a sample flow)
To better visualize what the components of a NiFi stream look like, let's look at a simple example, consisting of two processors and a connector:
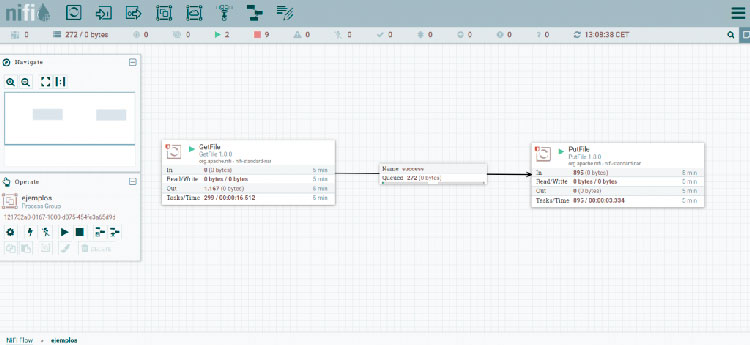
NOTE: In order to display the glued FFs, the processors have been slowed down. If this change had not been made, the process of changing the directory of the files would have lasted in the order of milliseconds, despite running on my local computer (which is far from resembling a production environment or a Big Data environment).
The first processor, which is of the GetFile type, collects files from a local directory. If we look at the information shown in its box, we will see that 1167 FFs have been output from it in the last 5 minutes. Of these FFs, 272 are still stuck in the connector (of type succes), waiting to be picked up by the processor of type PutFile. This processor simply puts the files in a local directory, having processed, as can be seen in the information on its box, 895 FFs in the last 5 minutes.
With these few elements, we would have mounted a simple NiFi stream, which moves files, in real time, from one directory to another within the local file system.
Working with NiFi
Having exposed this introduction of the main elements that compose a NiFi flow, it is easier to approach what this tool consists of: NiFi is an application designed under the paradigm of flow-based programming, a case, in turn, of the paradigm of data flow programming that entails a component-based development.
All this paraphernalia means that at an algorithmic level, the data flow can be designed at a high level, establishing a succession of actions (performed by the processors) on the data (contained in the FF), without having to worry about the internal logic of each of these operations. This creates networks of black box processes, which function as components that exchange data using the connections that have been predefined between them. In addition, we are dealing with a program with a graphic interface, which is operated mainly by drag and drop (to add processors or to establish the connections between them), adding one more aspect that allows us to move away from the great software developments full of lines of code. But, perhaps the most interesting thing about NiFi is the change of strategy that it proposes in terms of processing times and the volumes of data it handles.
The very idea of flow leads us to think of a continuous flow of volume controlled data. We are not dealing with a tool designed to carry out tasks in batches that are launched once a day and handle all the accumulated data at once. NiFi, is more a streaming tool, in which you work at the same time that things happen, treating the data record by record. And this is the door through which NiFi enters the world of big data, since in this way, it is possible to handle large volumes of data without investing in huge hardware resources, and the repercussions of an error are minimized, since a failure in the processing of a FF that stores a record does not spread to the rest of the data.
NiFi in the IOT coffee project
The intelligent socket that monitors the electricity consumption of the FutureSpace coffee machine, has no memory, does not store the data, so all its potential information ends up being lost.
In order to access the data it generates, it is necessary to perform HTTP queries to its API, with which you can know the current value at the time of the query. Therefore, if you want to monitor the power consumption of the coffee machine, it is necessary to perform these queries periodically, in relatively short intervals (for example, every 2 seconds). Moreover, it is not enough to collect this data, but it is necessary to store it in a system that gives it persistence.
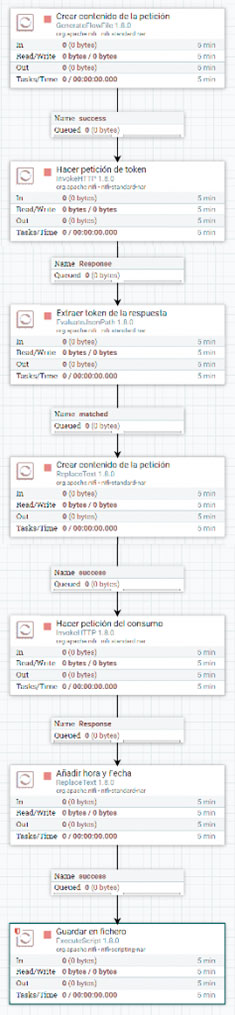
It would not be unreasonable to consider saving this data in some type of file (for example, in a csv format), so that the information can be handled and exploited later. Well, NiFi is designed to do, precisely, operations like the ones described above, so, for the IOT Coffee project the following flow was developed:
- Create request content:
This processor generates a new FF every 2 seconds. In the content of the FF is included the body (in json format) of the request that must be made to the plug API to obtain the authentication token, with which other requests can be made. - Make token request:
This processor calls the socket API, to make a POST request whose body is in the content of the previously generated FF. The result of this request, which includes the authentication token to request data from the socket, becomes the new content of the FF. - Extract response token:
For reasons of flow operation, it is necessary to extract the token that is in the content of the FF, and put it as an attribute or metadata of it, so that the token is not lost even if the content of the FF changes. - Create request content:
Once again, it is necessary to include in the FF the body of a request to the API, this time with the intention of obtaining the value of the consumption at the time of the request. - Make a consumption request:
A POST type request is made, similar to the one previously made to obtain the token, and the response obtains the instantaneous electricity consumption, which is stored in the FF. - Add time and date:
In order to enrich the consumption data, the date and time at which the query was made is added to the content of the FF, adapting this data to a format suitable for a csv file record. - Save to file:
Finally, the content of the FF is stored as a new line in a csv file that saves the history of electricity consumption of the coffee machine that records the plug.
NiFi, neither fu nor fa?
In FutureSpace, NiFi has been used in several projects (besides this vandalism act), and in all of them it has made us go through a rollercoaster of emotions. There have been moments of panic, of hate, of admiration, of frustration, of satisfaction... But the truth is that, deep down, I have the impression that I love NiFi. I think it's a great tool for doing what it does (streaming data management), and that maybe the problems will appear when it's used to do other things. What I'm not sure about is if we're the ones forcing its use, or if NiFi itself seems to be inviting you to go beyond its not-explicitly-defined comfort zone. In any case, when a group of vandals have had the opportunity to choose without restriction the tools with which to contaminate their company's coffee machine with IOT, their choice has been NiFi.
And what's inside the file where NiFi saves the power consumption data? We will see this in the following deliveries of Café con IOT
*Note on the sidelines... For the curious: What is Big Data?
BIG DATA In 1632, Galileo Galilei published Dialogo sopra i due massimi sistemi del mondo (Dialogue on the two main systems of the world), a book in which, in the style of the classical Greek dialogues, he exposes the conversations between a geocentric philosopher and a heliocentric one (logically, with the intention of defending the latter position). And this was the work that filled the glass of the "patience" of the Holy Inquisition, which condemned Galileo to life imprisonment, as well as to abjure his ideas regarding the movement of the celestial bodies. And Galileo abjured (in spite of the alleged eppur si muove). But what interests me about this work is that, at a certain point, it speaks of big data. [Dramatic pause for the reader to be shocked by the above statement]
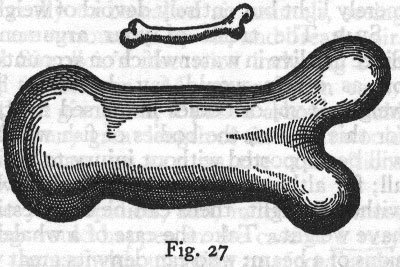
Image of Galileo's Dialogue What Galileo talks about in one part of his work is the changes of scale, in particular, what would happen to a bone, if the size of the animal it belongs to was increased. And the interesting thing is, he concludes that increasing something is not a linear process. When increasing the overall size of an animal, it is not enough to increase the size of the system that supports it (the bones), but there is a point where the system itself needs to be modified. And this is big data.
We could think that, when increasing the volume of data, what we must do is increase the resources to manage them (memory, processors, disk storage...). But this has not turned out to be the solution. What characterizes big data technologies is that, in order to do the same things with the data as always (store, process, consult, visualize...), they offer different solutions to those taken for smaller volumes. And they are not different on a whim, they are different for efficiency, because what works on one scale does not work on another, because scalability is not always a matter of more, but of another.








